





В этой статье
Причины для автоматизации процесса Code review
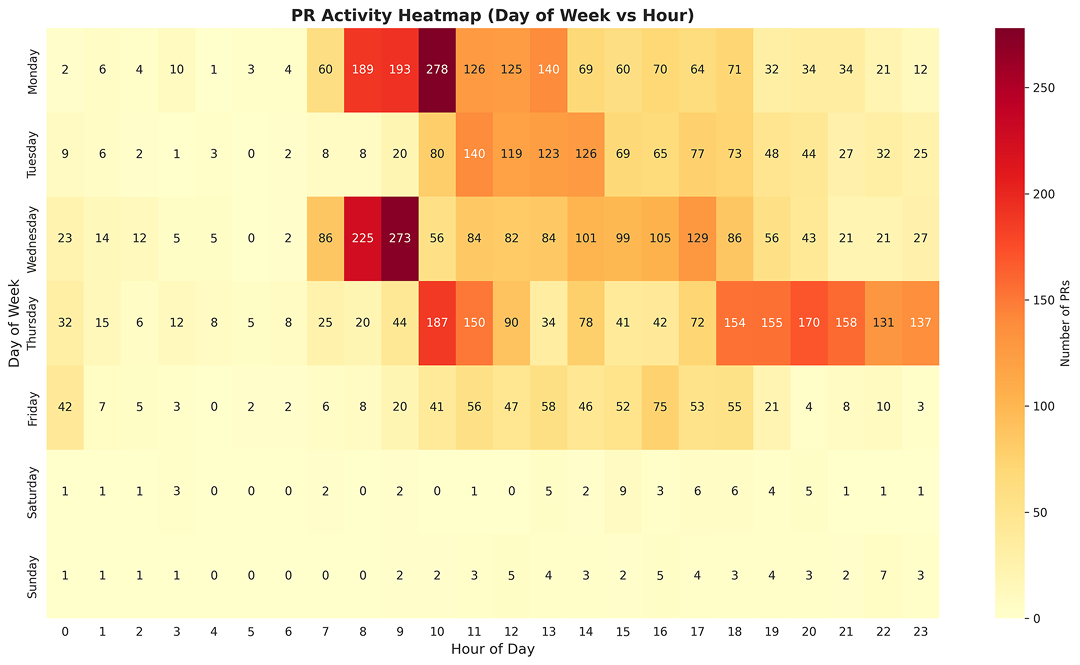
На карте видно, что в середине недели наибольшая нагрузка на ревьюеров
Архитектура системы Code review
- Stash — интерфейс, через который разработчики запускают ревью
- Go-сервис — регистратор событий и оркестратор процесса
- Python ML Pipeline service — сервис для генерации комментариев
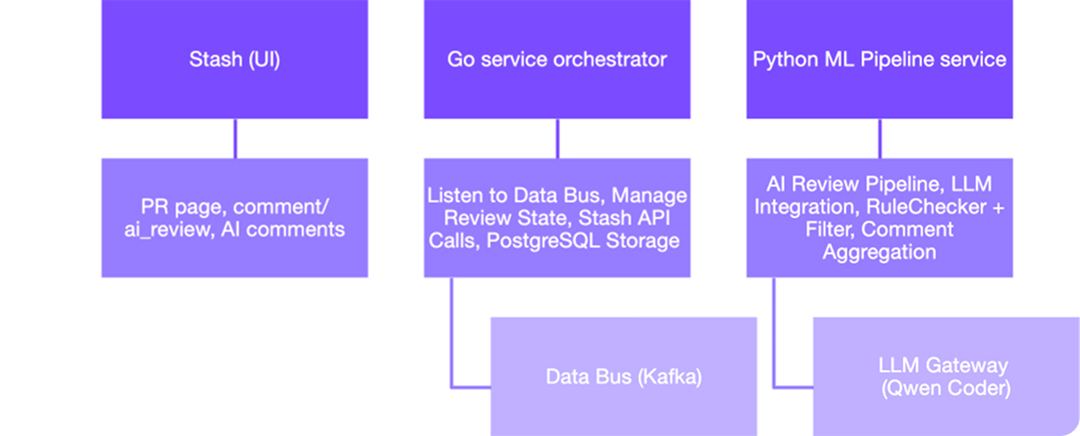
Разработчику достаточно в любом PR оставить комментарий ai_review. После этого сгенерируется событие, которое отправится в Data Bus, и уже оттуда его вычитает Go-сервис
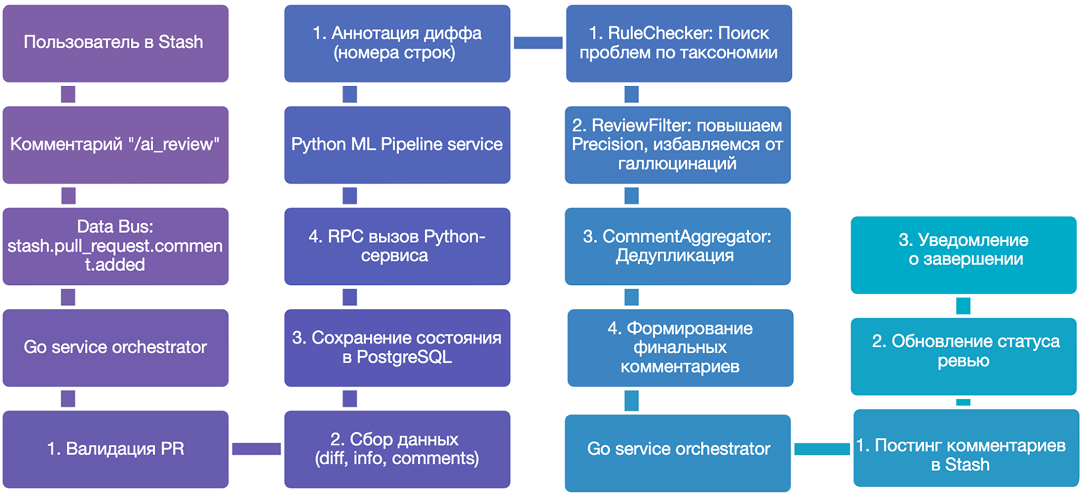
End-to-End поток запроса. В конце генерируются итоговые комментарии, которые уходят в Go-сервис и публикуются на Stash
Процесс по шагам
1. Запуск ревью из Stash. Пользователь оставляет комментарий ai_review, после чего генерируется Data Bus событие. Go-сервис получает его и парсит команду.
2. Подготовка данных. Go-сервис получает diff и такие метаданные, как структура репозитория и существующие комментарии. Далее кладёт ревью в базу со статусом STATE_REQUESTED. После этого отправляет RPC в ML-сервис.
3. Вызов ML-сервиса (RPC). Поскольку генерация может длиться долго, ML-сервис немедленно отвечает 200 OK, чтобы не блокировать Go-сервис и долго не держать соединение. После этого ревью переходит в статус BackgroundTaskRunner.
Выбор LLM-модели

Лидерборд моделей MERA-RuCodeReviewer: мы выбрали Qwen3-Coder-30B-Instruct-FP8 и она занимает второе место
Две причины селф-хостинга
Безопасность. Важно, чтобы весь код оставался во внутреннем контуре и не передавался во внешние системы через API.
Экономика. По нагрузке генерации получаются токеноёмкими: для небольших PR это около 2 000 токенов, а для крупных — до 10 000. При таких объёмах использование API становится дорогим, тогда как собственные ресурсы у нас уже есть. По сравнению с API-моделью селф-хостинг позволяет снизить стоимость без потери качества.
Этапы ML-пайплайна
…
@@ -45,7 +45,9 @@ def process_data(data):
if data is None:
- return None
+ raise ValueError ("Data cannot be None")
……
@@ -45,7 +45,9 @@ def process_data(data):
[unchanged] if data is None:
[deleted or pre-modified @46 in old code] - return
None
[added or post-modified @46 in new code] + raise
ValueError ("Data cannot be None")
…- безопасность;
- дефекты разработки;
- перфоманс;
- поддержка кода.
Итог этапа — модель генерирует JSON-массив, где для каждого замечания сохраняются:
- строка кода, к которой относится комментарий;
- категория проблемы;
- текст замечания;
- рекомендация по исправлению.
Этап 2. ReviewFilter. Валидация. На этом этапе мы повышаем точность, чтобы не перегружать разработчиков избыточными комментариями. Фильтр отсеивает false positives и нерелевантные замечания, оставляет только важные проблемы. При этом модель генерирует краткое обоснование, почему она посчитала комментарий важным или нет.
Модель работает в паттерне Conclusion First. Мы передаем ей тот же контекст (diff и полный файл), а также конкретный комментарий, привязанный к строке кода. Задача модели — ответить «да» или «нет» на вопрос «является ли это замечание действительно важным». Все комментарии, которые получают «нет», мы отбрасываем.
Этап 3. CommentAggregator. Дедупликация. Мы строим эмбеддинги комментариев с помощью модели BAAI/bge-m3 и вычисляем их семантическую близость. Если cosine similarity комментариев превышает 0.85, они группируются. Внутри каждой группы (при условии, что комментарии относятся к одной строке) мы оставляем один наиболее содержательный и корректный. В результате формируется финальный JSON со списком уникальных комментариев, который передается в Go-сервис и далее отображается пользователю.
Финал. Python-сервис завершает процесс ревью и вызывает RPC у Go-сервиса. Go-сервис устанавливает статус STATE_FINISHED и после этого через API публикует все комментарии, сгенерированные моделью. Именно их в итоге видит разработчик в интерфейсе — без дублирующихся комментариев и лишней информации.
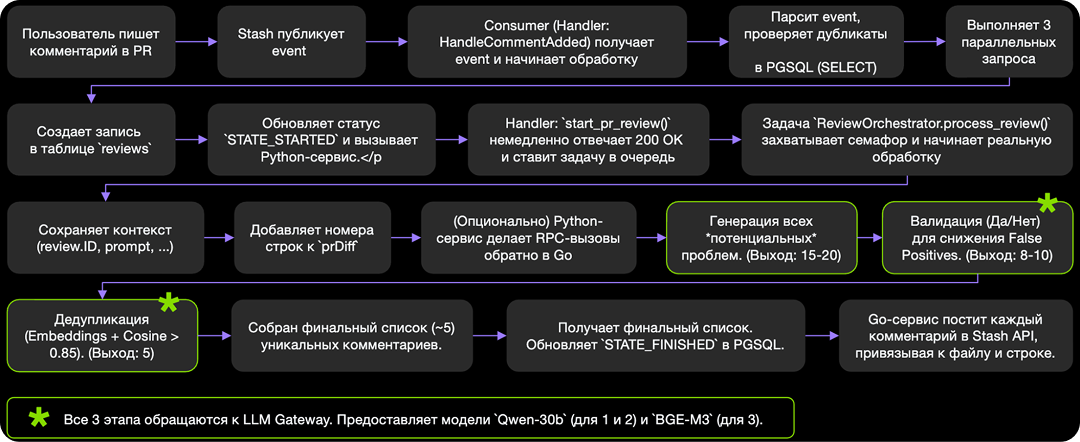
Детальный ML-пайплайн, на котором описаны все этапы
Производительность решения. На демо-репозиториях мы собираем усредненный diff. Пул-реквесты условно делим на малые — до 3 файлов и большие — 10+ файлов. Малые пул-реквесты обрабатываются за 10–20 секунд. Большие — примерно за 60 секунд.
Для стабильной работы мы ограничиваем количество параллельных ревью до 650 штук. Это число получили из анализа нагрузки, и специально дополнительно завысили, чтобы оставить ресурс на расширение.
Метрики решения

Пример генерации. В одном из пул-реквестов неправильно указали диапазон времени — не по московскому времени. Модель предложила исправить диапазон, и разработчик поставил лайк
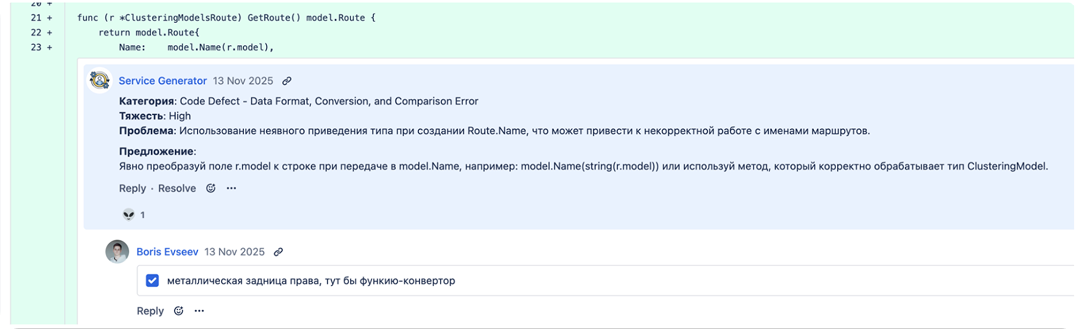
Высокая оценка DS-специалиста

Outdated rate можно разделить по категориям репозиториев. Например, в Infra и DevOps метрика достигает 60%, что даже для человеческих комментариев считается высоким результатом
Вместо выводов
Больше про DS и ML рассказываем в нашем телеграм-канале «Доска AI-объявлений». Пишем про ИИ, делимся вакансиями и анонсируем интересные мероприятия.
→ Заглянуть
