




Привет! Меня зовут Иван Кравцов, я инженер в команде автоматической модерации Авито. В этой статье расскажу приключенческую и немного детективную историю дебага проблем С-уровня в Python.

«… Эта история начинается довольно банально. Она начинается с дома».
Дуглас Адамс, «Автостопом по галактике»
Как и известный роман Адамса, моя история начинается довольно банально. Она начинается с рефактора.
Задача
Не так давно я занимался проектом по распилу монолитной системы автомодерации. Моей задачей было выделить из нее крупный блок логики, связанный с поиском дубликатов объявлений. Требовалось переосмыслить порядка 60 000 строк кода на Python, разработать новую архитектуру и аккуратно смигрировать систему.
Целью было, с одной стороны, разделить системы по доменам, с другой — сэкономить ресурсы, оптимизировав работу выделенного компонента.
С чем предстояло работать
Поиск дублей — одна из наиболее ресурсоемких наших компонент. Входящая нагрузка — до 1500 rps. Система занимается поиском кандидатов в дубли, а затем попарно сравнивает каждого кандидата с опорным объявлением. В большей части сценариев мы рассматриваем до 300 кандидатов, так что пиковая нагрузка оказывается 1500 * 300 = 450 000 rps.
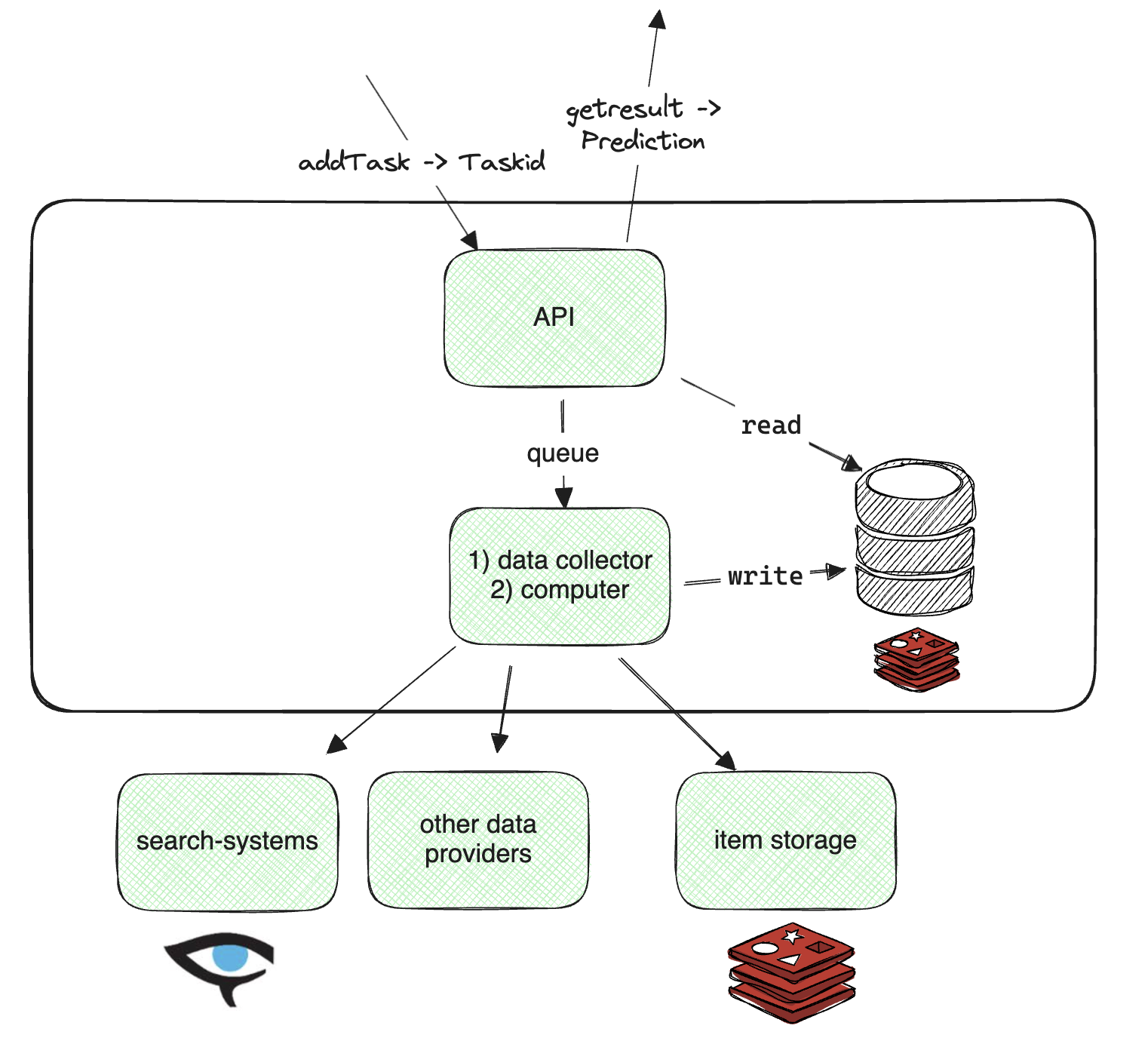
Получившийся сервис состоит из одного главного деплоймента, развернутого в большом числе реплик (порядка 600 штук на момент описываемых событий). На входе очередь (Redpanda), из которой воркеры читают батчи сообщений и после обработки складывают результаты в базу, откуда их можно получить по API. Вычислительная часть включает в себя много различного ML (scikit-learn, fasttext, xgboost, lightgbm, catboost, scipy, Python-Levenshtein и другие либы).
Опущу часть про разработку и синтетические тесты. Интересное началось в момент, когда я подключил систему к продакшн-трафику в дебаговом режиме.
Достаточно редко — скажем, несколько раз в сутки, — мы получали сообщения, обработка которых приводила к одной из ошибок работы с памятью: corrupted size vs. prev_size, corrupted double-linked list и т.д. Под, получивший такое сообщение, умирал без возможности перехватить исключение, offset в очереди не сдвигался, после чего шар смерти проблемное сообщение получал следующий под, который также падал.
Подъем нового пода занимает около одной минуты, в то время как обработка сообщения — порядка 5-10 секунд. Это приводит к тому, что одно «битое» сообщение могло вывести из строя сразу целую группу подов. И если таких сообщений оказывалось несколько одновременно, система начинала заметно деградировать. Единичные сообщения оказались способны вывести из строя систему, рассчитанную на нагрузку 1500 rps.
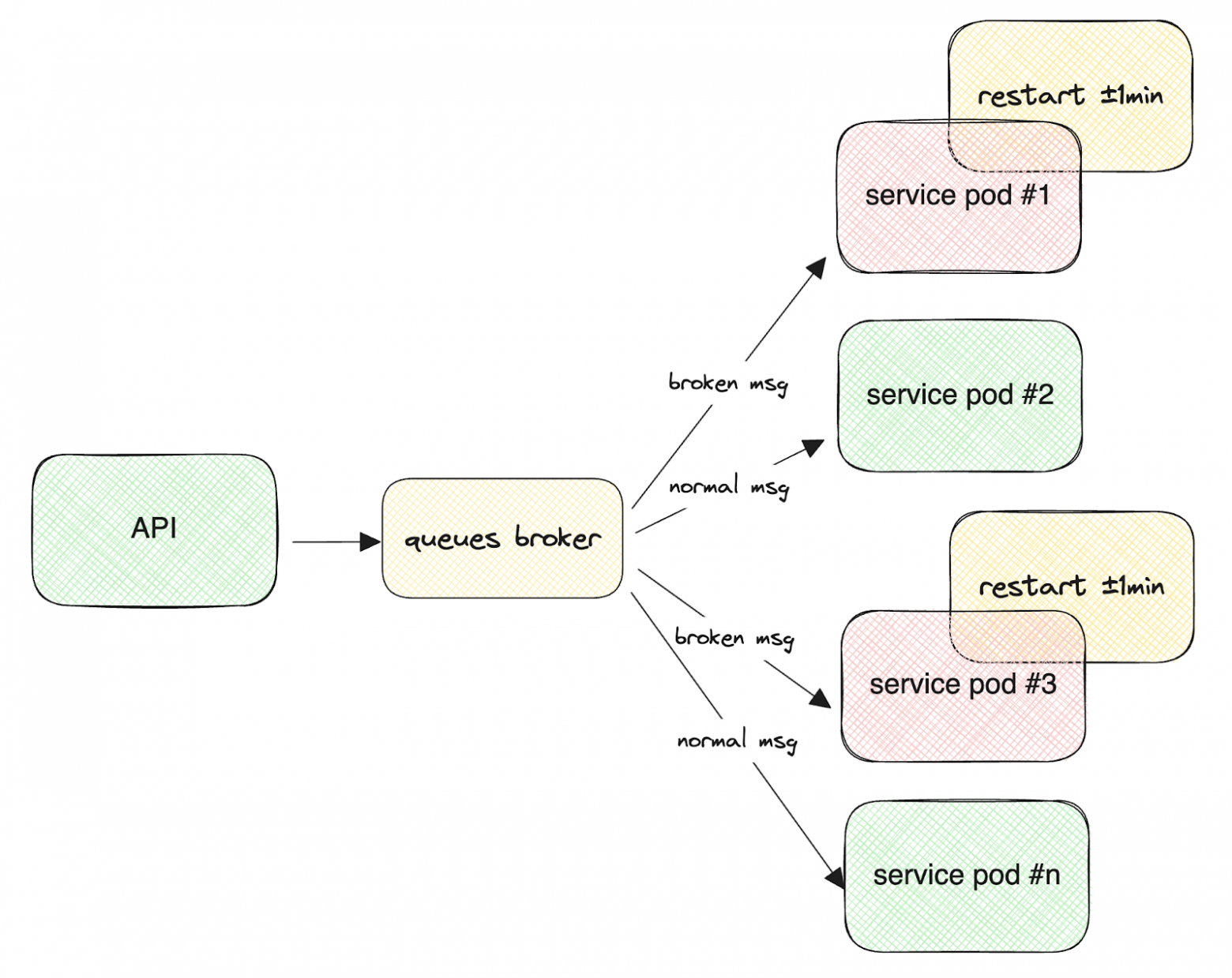
Скучный спойлер: после решения проблемы мы добавили механику трекинга числа попыток обработки и пропуска сообщений после n попыток.
Итого, что мы имеем:
- проблемных сообщений крайне-крайне мало. Простой запуск на проблемном сообщении к ошибке не приводит;
- поды получают SIGABRT. Перехватить ошибку или тем более записать корки из Python не представляется возможным. Логами проблему удалось локализовать до группы моделей, в которых она возникает. Однако глазами по коду найти проблемную точку не удавалось;
- ещё более запутанным ситуацию делало то, что проблемное сообщение в конце концов удавалось обработать — на это могло уйти рандомное количество попыток.
Расследование
Пришлось погрузиться в расследование.
Первым делом мне нужно было собрать в проде стенд для экспериментов.
Идея очень простая. Мне нужен отдельный воркер, способный читать реальные сообщения, в котором я смогу запускать отладочный код. Чтобы гарантировать, что проблемное сообщение прочитает только он — добавил возможность отключать чтение в остальных воркерах. Иначе, однажды поймав «битое» сообщение, мне пришлось бы долго ждать, пока оно попадет в мой воркер снова.
Написав немного кода, затаился и принялся ждать.
Дождавшись проблемного сообщения, отключил чтение во всех подах, кроме моего фейкового воркера-стенда. В нем вручную запустил ридер с логированием каждого входящего сообщения. Дождался падения, сохранил тело сообщения для отладки. В этот момент я, наконец, получил полный стейт битого сообщения для экспериментов.
Мои руки были развязаны благодаря тому, что система работала в дебаге и я мог отключать ее без влияния не качество модерации. Если пофантазировать и представить подобную отладку на полностью «боевой» системе, вероятно, самым разумным было бы поднять отдельную очередь и воркера, подключенного только к ней. А потом паблишить в эту очередь только кандидатов в битые сообщения прямо из основного ридера.
Однако это не наш случай, так что пора вернуться назад — в момент, где мне удалось получить стейт сообщения вызывающего ошибку.
Проанализировав тело сообщения, никаких аномалий обнаружить не удалось — это было рядовое объявление: ни больших текстов, ни огромного числа изображений, ни чего-то еще подозрительного. Позже выяснилось, что одного стейта сообщения для воспроизведения проблемы недостаточно.
Далее я принялся дебажить Python.
Собрал в стенде дебаговый Python с дополнительными CFLAGS для поддержки gdb в режиме отладки памяти.
apt-get install build-essential gdb lcov pkg-config \libbz2-dev libffi-dev libgdbm-dev libgdbm-compat-dev liblzma-dev \libncurses5-dev libreadline6-dev libsqlite3-dev libssl-dev \lzma lzma-dev tk-dev uuid-dev zlib1g-dev -ywget -c https://www.python.org/ftp/python/3.10.13/Python-3.10.13.tar.xztar -Jxvf Python-3.10.13.tar.xzmkdir Python-3.10.13/build && cd Python-3.10.13/build../configure --with-pydebug --without-pymallocmake EXTRA_CFLAGS="-DPYMALLOC_DEBUG -DPy_REF_DEBUG"ln -s ./python /usr/local/bin/python-debugcd /apppython-debug -m ensurepip --upgradepython-debug -m pip install poetry==1.8.1python-debug -m poetry installgdb --args python-debug lib/jobs/scoring_worker.py
Сохранив проблемное сообщение, переписал ридера так, чтобы он читал только его. Запустился под gdb и, наконец, нашел адекватную зацепку:
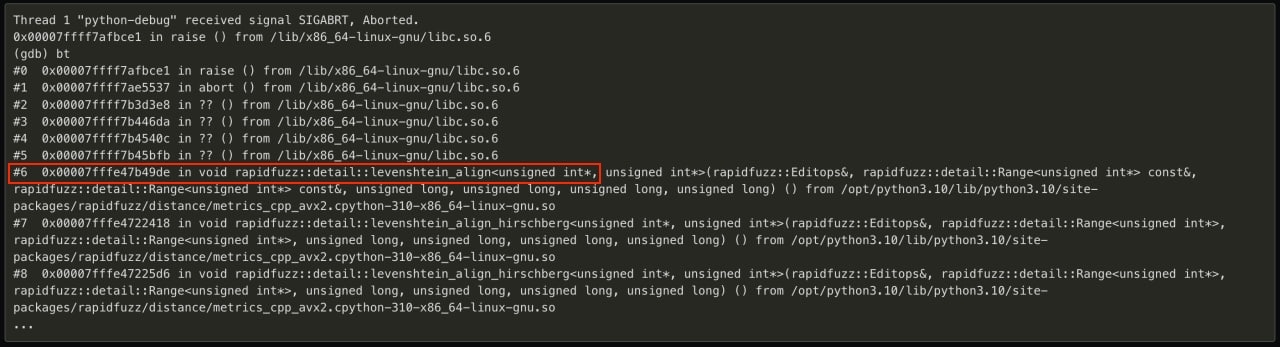
Вооружившись знанием, что проблема где-то в точке использования rapidfuzz, расставил breakpoint по коду и эмпирически нашел конкретную точку. Залогировав конкретные стейты текстов, используемые в этой точке, зашел в мейнтейнеров либы с issue на починку с воспроизводимым примером.
Как оказалось, проблема возникает при определенной комбинации предобработанных текстов опорного сообщения и одного из кандидатов.
Этим объясняется тот факт, что битое сообщение рано или поздно удавалось обработать. Мы получаем кандидатов из отдельных поисковых систем, где в какой-то момент меняется стейт (например, в результате gc). В итоге на n-ной попытке обработки опорного проблемный кандидат не находится и ошибка не возникает.
Итог
Отладка проблемы заняла у меня несколько дней. Большая часть этого времени ушла на размышления и попытки построить тестовый стенд. Для меня эта история, помимо увлекательного (надеюсь!) сюжета, во-многом о том, что зачастую правильная идея для воспроизведения проблемы заметно важнее самого процесса отладки и устранения проблемы. Так что хорошо делайте, а плохо — нет желаю всем отличных и правильных идей. Спасибо за уделенное статье время!
Больше о том, какие задачи решают инженеры Авито, — на нашем сайте и в телеграм-канале AvitoTech. А вот здесь — свежие вакансии в нашу команду.
