




Привет! Меня зовут Наталия Вареник, я DS-инженер в Авито, занимаюсь моделями распознавания изображений. Расскажу про один из наших проектов — пайплайн для распознавания номеров с фотографии свидетельства транспортного средства (СТС). В статье описала особенности задачи и рассказала, как мы решали её с помощью декомпозиции.
Материал будет полезен начинающим и мидл-DS-инженерам, которые хотят узнать больше про декомпозицию задачи на этапах разметки и построения моделей.
А еще материал стоит прочитать тем, кто работает с доменами, где нужно иметь дело с задачами распознавания информации с документов — наш подход прекрасно переносится на другие категории. В целом рекомендую статью всем, кто интересуется компьютерным зрением и его применимостью в разных сферах.

Суть задачи
Пользователям сложно проходить проверки на Авито — мы требуем много информации с документов, в которой легко ошибиться, если вводить вручную. Мы следим за качеством контента на площадке, поэтому на этапе подачи объявления просим много подтверждённых данных.
Так, чтобы разместить объявление о продаже машины на Авито, мы просим продавцов добавлять в объявление фото машины, VIN и госномер.
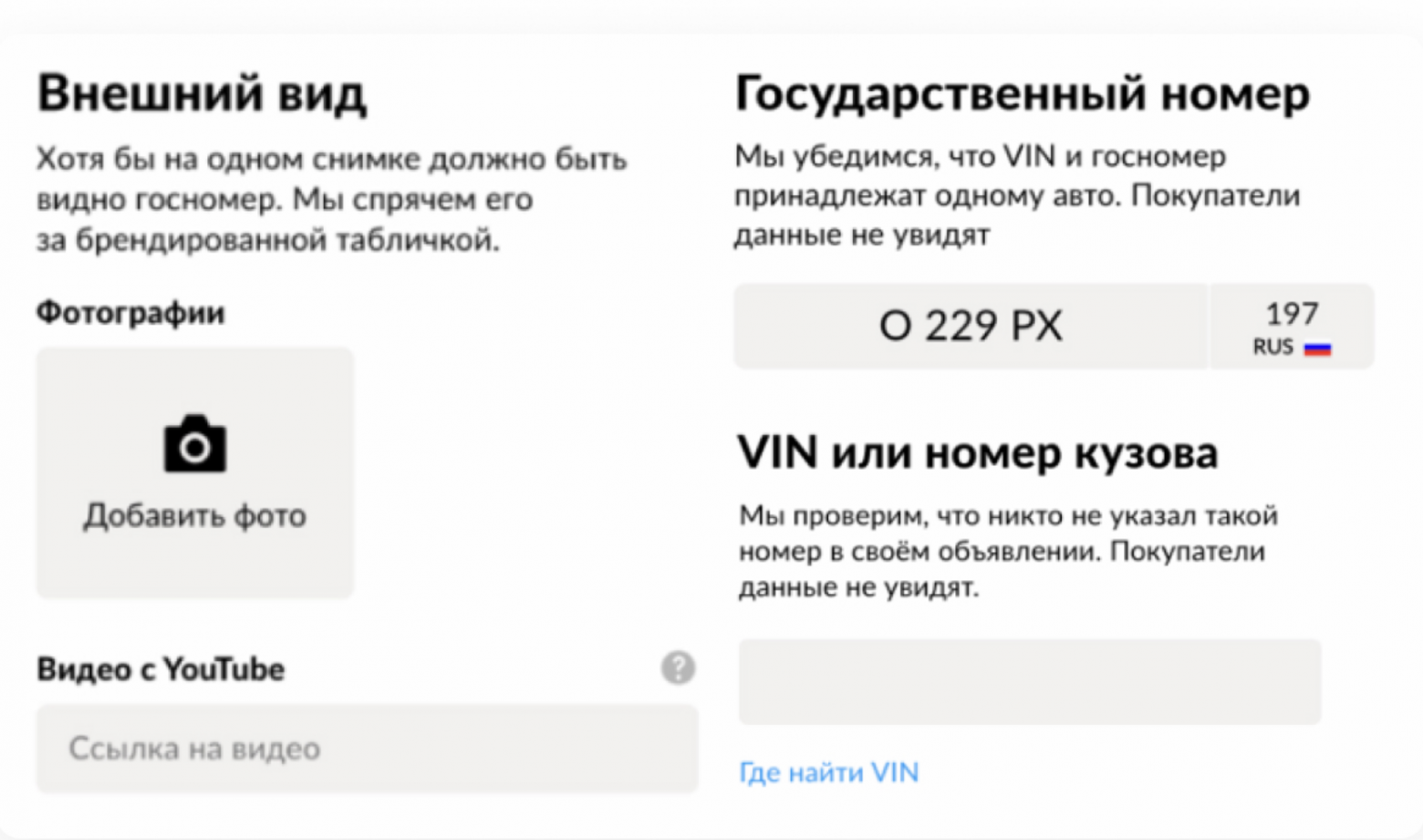
Поля на подаче объявления, куда пользователи вводят данные об авто
Все данные, которые добавляют пользователи, мы проверяем на соответствие.
VIN и госномер — это длинные последовательности символов, в которых легко ошибиться при ручном вводе. Но эти данные важны, так как, например, по VIN-номеру мы смотрим историю автомобиля, а потом сверяем его с госномером.
Часть пользователей уставали заполнять форму отправки объявления. Часть заполняли всё, но объявления не проходили модерацию из-за ошибок в VIN или госномерах. Из всех отказов в публикации объявлений 8% мы отклоняли именно по этой причине.
Многие пользователи обращались в поддержку, когда заполнить данные не получалось, и нагрузка на сотрудников саппорта росла.
Мы хотели найти решение, чтобы повысить процент объявлений, которые успешно проходят модерацию, упростить процесс ввода данных для пользователей и снизить нагрузку на саппорт.
Этим решением стала модель, которая автоматически заполняет поля для VIN и госномера по фотографии свидетельства транспортного средства — СТС.
Проанализировали задачу и сформулировали требования к модели
Было четыре основных требования:
Высокая точность. На основе данных про авто принимаются важные решения, поэтому ради точности мы были готовы пожертвовать ресурсами.
Переносимость на другие домены — чтобы мы или коллеги в дальнейшем могли решать запросы на распознавание данных с фото по уже проработанному пайплайну.
Масштабируемость под продовую нагрузку — чтобы мы легко могли увеличить пропускную способность и скорость обработки, и модель не легла под большим потоком пользователей. Например, это будет полезно, если другие команды тоже начнут использовать нашу модель для распознавания данных.
Устойчивость к вариативности данных — об этом расскажу дальше.
Что мы знаем о данных
Для распознавания данных мы решили взять свидетельство транспортного средства (СТС). Это обязательный документ для автовладельцев, который подтверждает, что машина зарегистрирована и может законно находиться на дороге.
Выглядит это так:
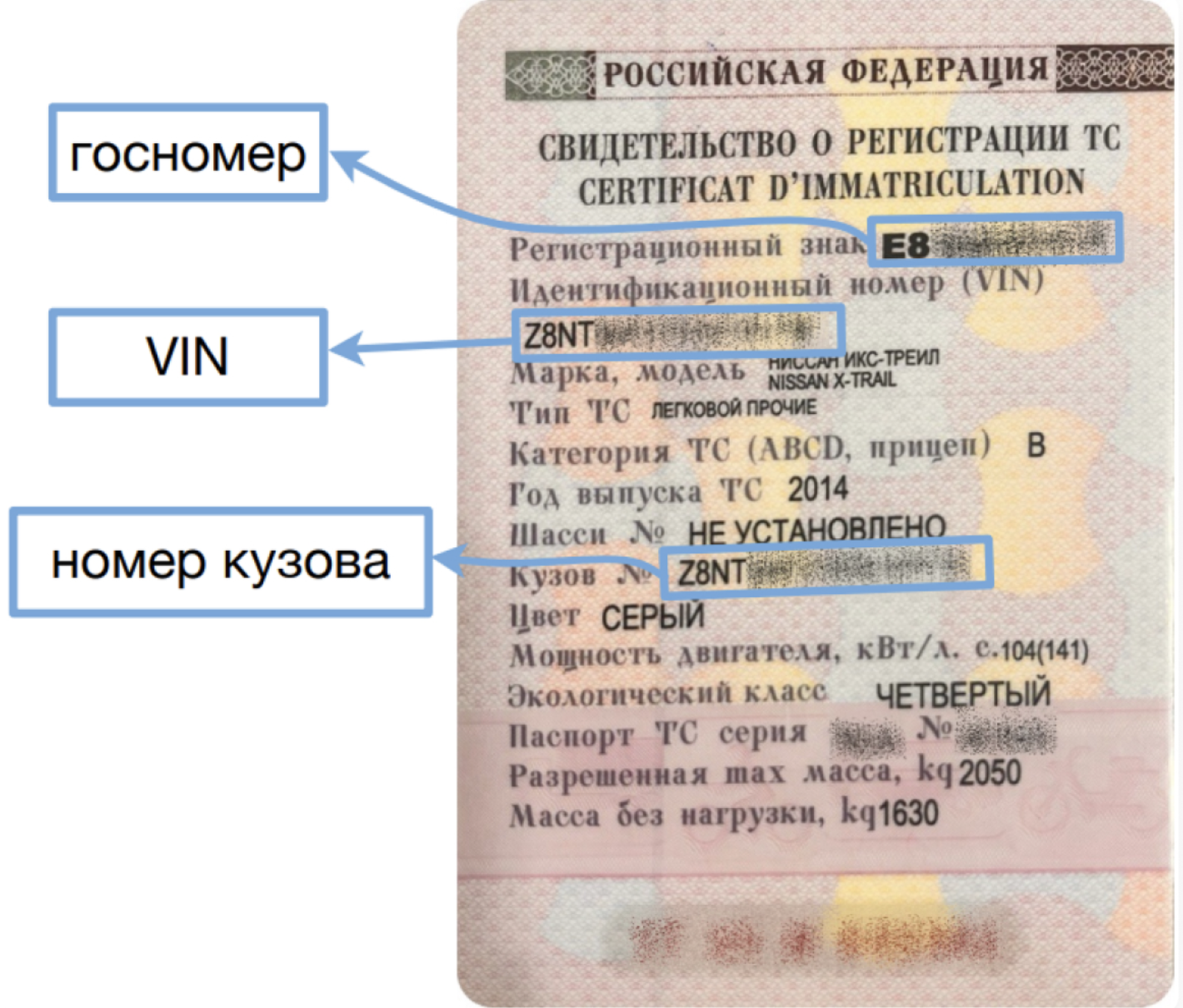
Пример свидетельства транспортного средства с указанием нужных нам полей — госномер, VIN, номер кузова
Дисклеймер: все фотографии документов предоставили для статьи мои коллеги. Мы не публикуем персональные данные пользователей.
В процессе работы мы поняли, что разные СТС могут отличаться друг от друга. И из-за этого возникли некоторые сложности.
Первая сложность — в участках нанесения номеров. Хотя СТС — это документ с чёткой структурой, конкретные области с нужными номерами могут отличаться.
Есть ещё одна особенность — различия в VIN или идентификационном номере транспортного средства. У большинства машин — обычный VIN, который состоит из 17 символов и совпадает с номером кузова. Но у старых японских машин в графе VIN часто пишут слово «Отсутствует», а вместо него в качестве идентификатора используют номер кузова:
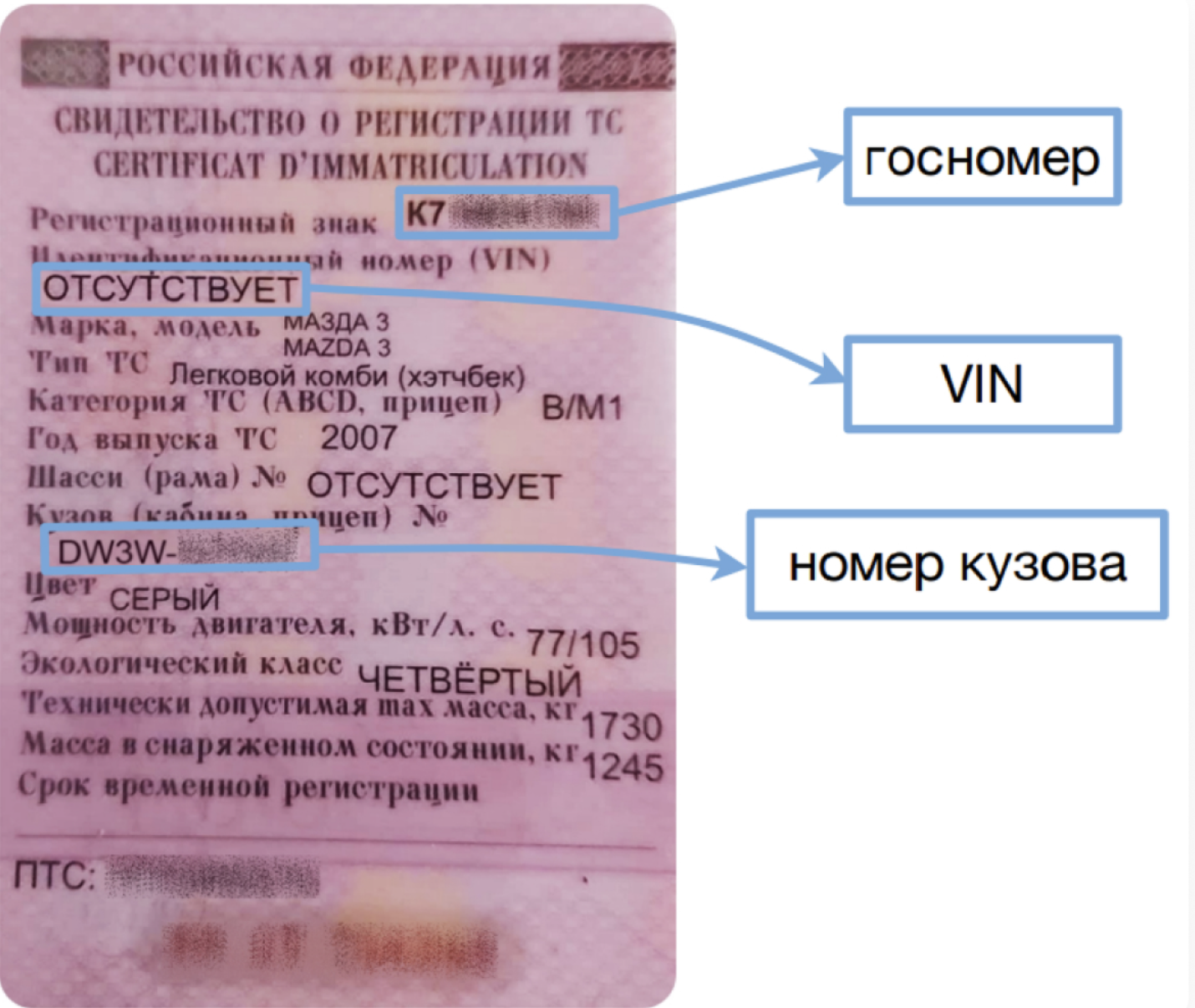
Так выглядит «японский» СТС без идентификационного номера
И хотя нам нужны только VIN и госномер, модель всё равно должна уметь распознавать ещё и номер кузова:
- в случае с «обычным» СТС, номер кузова поможет точнее распознать VIN, если с нужной области корректно распознать не получилось;
- в ситуации с «японским» СТС, мы будем использовать номер кузова вместо отсутствующего VIN.
У самих номеров тоже есть особенности и чёткая структура:

Характеристики и примеры разных типов данных — госномера, «обычного» и «японского» VIN
Начали с тестирования опенсорсных-решений
Перед разработкой своей модели мы попробовали поработать с тремя популярными end-to-end решениями, которые подходят под задачу, а после сравнили результаты.
Требования к решениям: точность > 95%, полнота > 90%. Оценку точности свели к бинарным кейсам: распознали / не распознали.
Библиотеки, которые мы использовали, с документацией на GitHub:
🔗 DocTR
🔗 EasyOCR
Сравнили результаты:
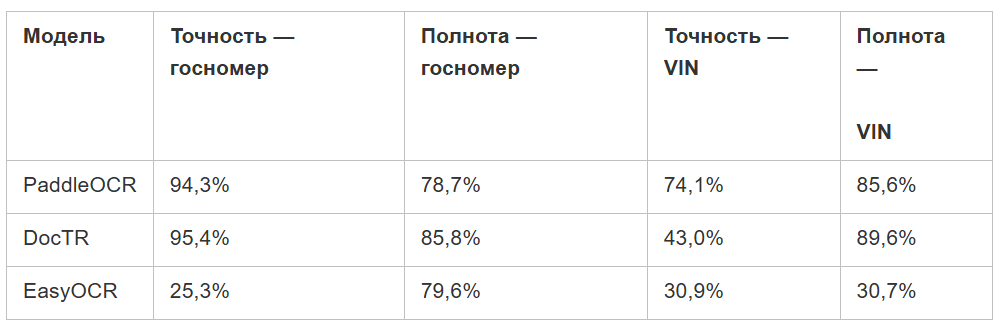
Лидером стал PaddleOCR, но даже это решение не вписывалось в требования. Мы разобрали ошибки и обнаружили, что модель:
- пропускала нужные номера на этапе детекции;
- допускала ошибки в одиночных символах;
- делала ошибки на концах номеров из-за наложения другого текста или близкого соприкосновения;
- склеивала два слова из строки в одно.

Пример распознавания текста с помощью PaddleOCR — слева фотография СТС, справа — текст, который распознала модель
После всех тестов мы решили не докручивать опенсорсное решение, а сделать свой лёгкий в использовании пайплайн под конкретную задачу.
Решили разработать своё решение и разбили его на 3 этапа: проверочные модели, детектор, OCR
Очень высокой точности распознавания мы добились с помощью декомпозиции. Это значит, что решение состоит не из одной модели, которая делает все задачи по распознаванию, а из нескольких моделей с узкой «зоной ответственности». При этом каждая из этих промежуточных моделей готовит данные для следующего этапа.
Пайплайн состоит из трёх этапов:
- проверочные модели — проверяют исходную фотографию свидетельства и, если она некачественная, возвращают её пользователю с подсказками по улучшению. Так мы не будем плодить ошибки распознавания на некачественных данных и поможем автору объявления дойти до публикации;
- детектор — выделяет и вырезает области с нужными номерами из исходных фотографий;
- OCR — распознаёт номера.

Пайплайн модели распознавания данных по фотографии СТС
Сделали проверочные модели для анализа пользовательских снимков СТС
Первый шаг после того, как пользователь загрузил фотографию документа — проверить снимок с помощью классификаторов. Они определяют:
- какой тип документа на фото — если это не СТС;
- видно ли в кадре СТС полностью;
- насколько далеко находится СТС на фото.
Во всех этих случаях, если фото не удовлетворяет нашим требованиям, мы отказываем в распознавании и даём пользователю подсказку.
Ещё определяем, под каким углом сфотографировали СТС. Если фото сделали под углом или с перспективой, исправляем до нормального положения. На этом этапе можно добавить дополнительные параметры проверки — например, размытость, тени и блики в важных местах.
Внедрили детектор для распознавания положения номеров на фото
Детектор мы обучали на собственной разметке — датасете из фотографий документов, где руками были выделены области с номерами.
Поскольку текст на самом документе может быть под углом, для выделения нужных областей мы использовали ориентированные четырёхугольники — так в области не попадёт лишний текст.
Разделили разметку на два проекта, чтобы проверить качество работы асессоров. В рамках первого просили выделить номера, во втором — просили проверить качество по критериям.

Два проекта с асессорами
Затем контролировали точность разметки во втором проекте. Для этого использовали голден — набор примеров, где мы знаем эталонные ответы. Эти примеры случайно подмешивали асессорам, после чего сравнивали эталонные ответы с теми, что дали асессоры. Считали долю правильных ответов и ошибок.
Таким образом мы оценивали качество работы как отдельных асессоров, так и разметки в целом.
Благодаря декомпозиции получилась очень точная разметка.
Для детекции использовали сегментационную модель U-Net, потому что она позволяла очень тонко выделить область с номером. Обучили модель на два класса: 1 — пиксель принадлежит маске одного из номеров, 0 — часть фона. На выходе получаем маску, которая накладывается на изображения и показывает, где расположены номера:

Фотографии СТС с масками, сделанными архитектурой U-Net
Для повышения точности провели аугментацию — добавляли на фотографии размытие, засветы, затемняли их. Это помогло получить более точные границы на размытых фотографиях и исключить разрезы маски из-за бликов на номерах.
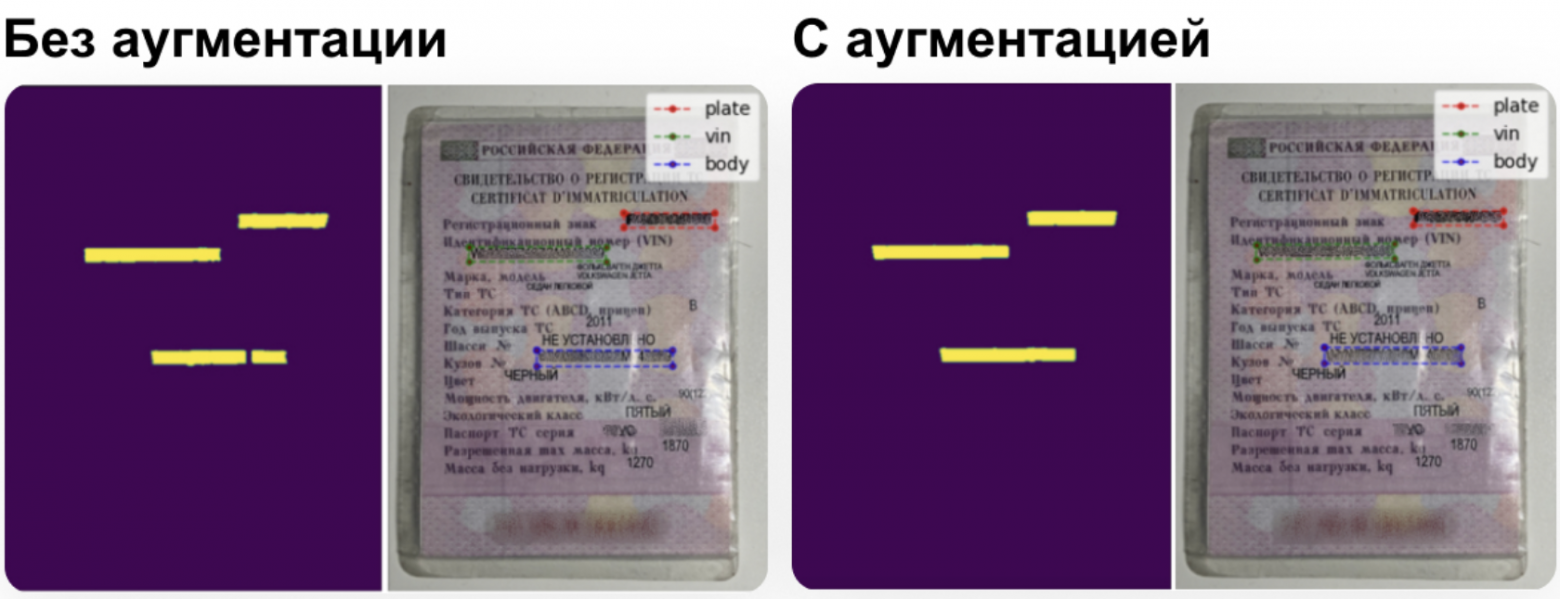
Значение надписей на плашке в верхнем правом углу: plate — госномер, vin — вин, body — номер кузова
Мы получили улучшенный результат на данных с размытостью и засветами, так как модель видела это на обучении и училась, как работать в таком случае.
Эта модель хорошо работала на большинстве фотографий, но давала неточности на изображениях с большой перспективой, отдалённостью, или, если снимки были сделаны под углом. Мы пытались добавлять фотографии под углом в данные, но этого было недостаточно — маски всё равно искажались.
Добавили блок для выравнивания документа перед этапом детектирования. Если пользователь присылает фотографию под углом или с перспективой — мы поворачиваем её до нормального положения и корректируем перспективу.
Для выравнивания используем архитектуру RetinaNET — находим четыре координаты углов документа, по ним определяем границы, обрезаем фон и выравниваем.
Для коррекции перспективы применяем warpPerspective. Это функция в OpenCV Python, которая применяет аффинное преобразование к картинке, которое убирает перспективу.
Нам она нужна, чтобы убрать перспективу на фотографиях СТС, которые были сделаны не строго сверху:
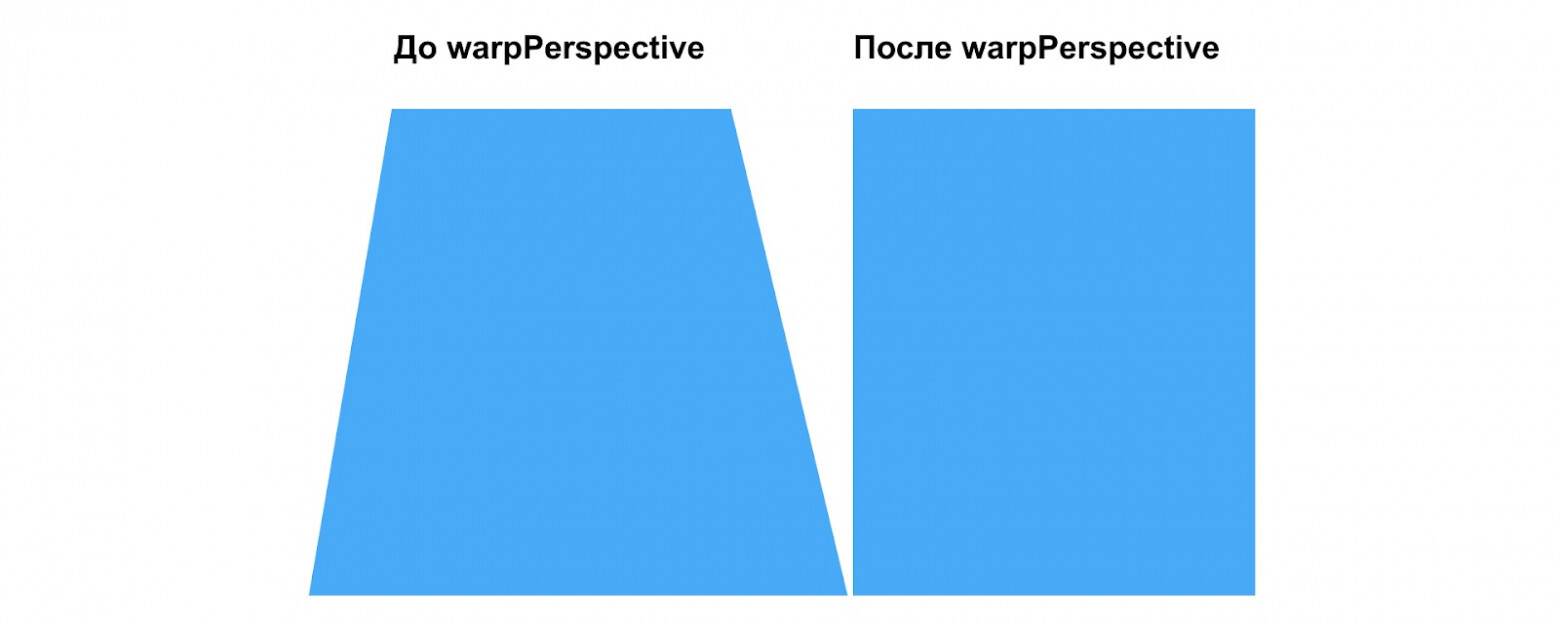
На выходе получаем документ в нормальном положении с обрезанным фоном

Фотография до и после выравнивания с помощью RetinaNET
Использовали OCR для распознавания текста
На последнем этапе модель распознаёт номера на кусочках из исходной картинки, которые вырезали по маске из детектора. Для распознавания текста мы обучили свёрточно-рекуррентную архитектуру CRNN с CTC-декодером и датасетом из пар: «картинка + текст».
По маске с предыдущего этапа мы вырезаем области с номерами из фотографий и выравниваем их:
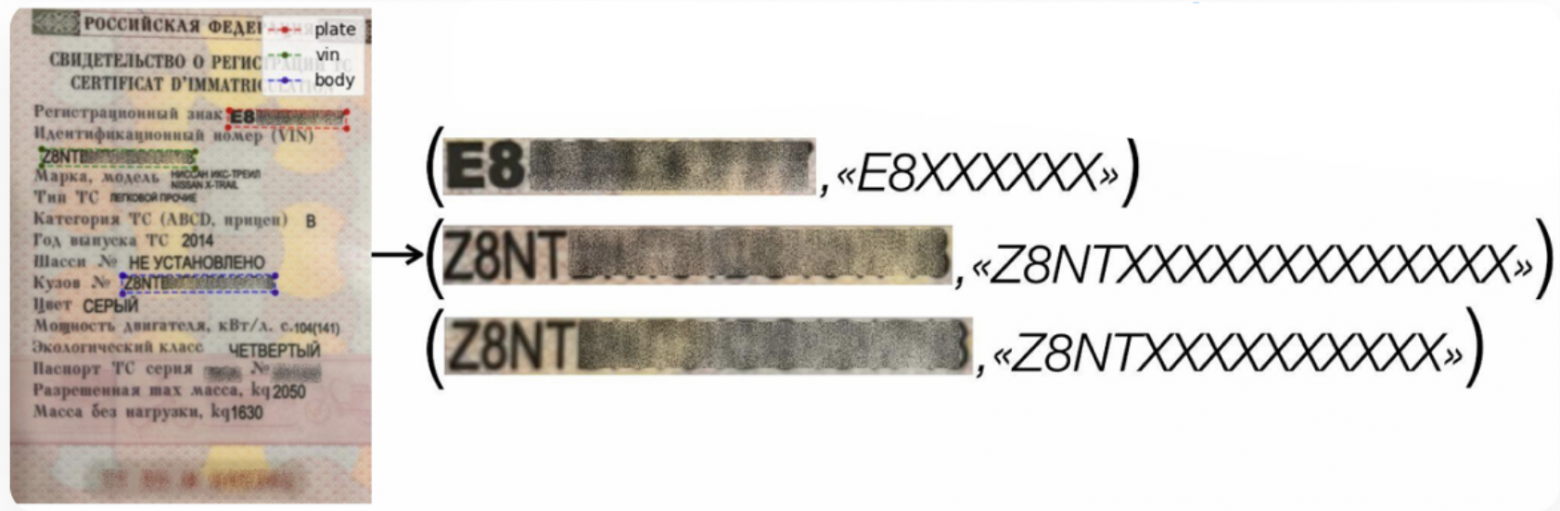
Обрезаем и выравниваем фотографию по маске от детектора
После распознавания текста номеров мы применили валидационные правила, чтобы проверить или скорректировать результаты. Это нужно для большей точности. Правила построили на основе знаний о структуре номеров.
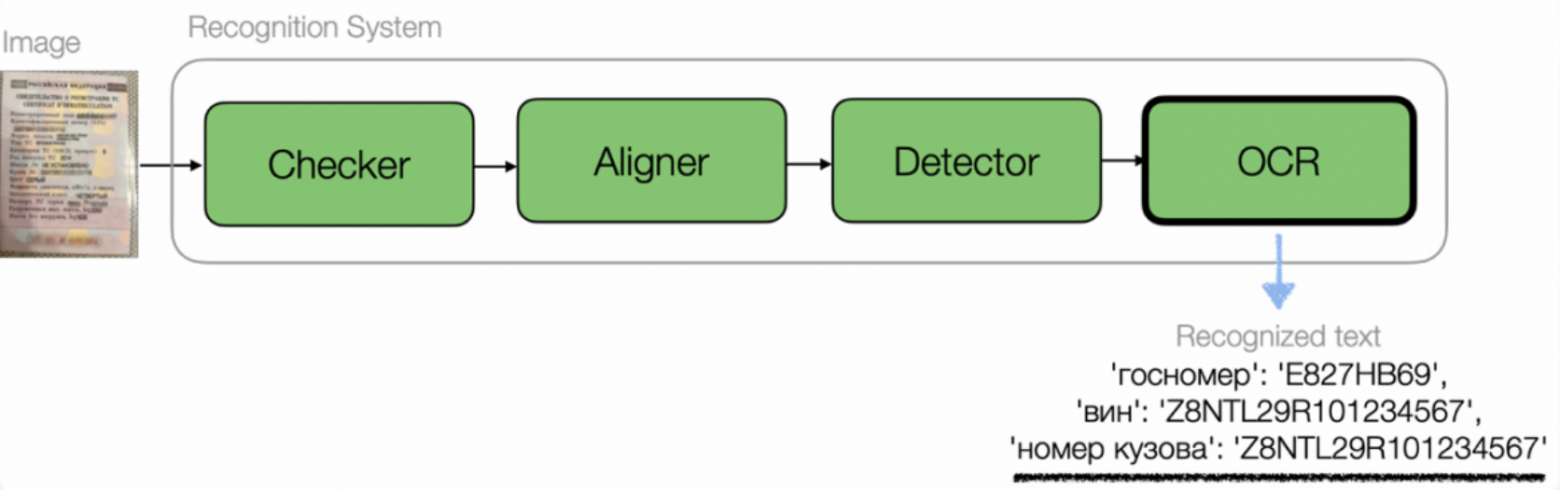
Все этапы распознавания номеров на одной картинке
Результаты: попали в целевые метрики и получили показатели выше ожидаемых
Провели тесты нашей модели и смогли побить пороги, которые ставили ещё до разработки. Получили такие значения:

Также мы собрали данные по ошибкам после внедрения модели. На графике видно, что она не смогла распознать текст только у 8% фотографий. В остальных случаях модель либо распознала всё успешно, либо мы дали подсказки, как исправить ошибки, и она распознала нужные данные после этого.
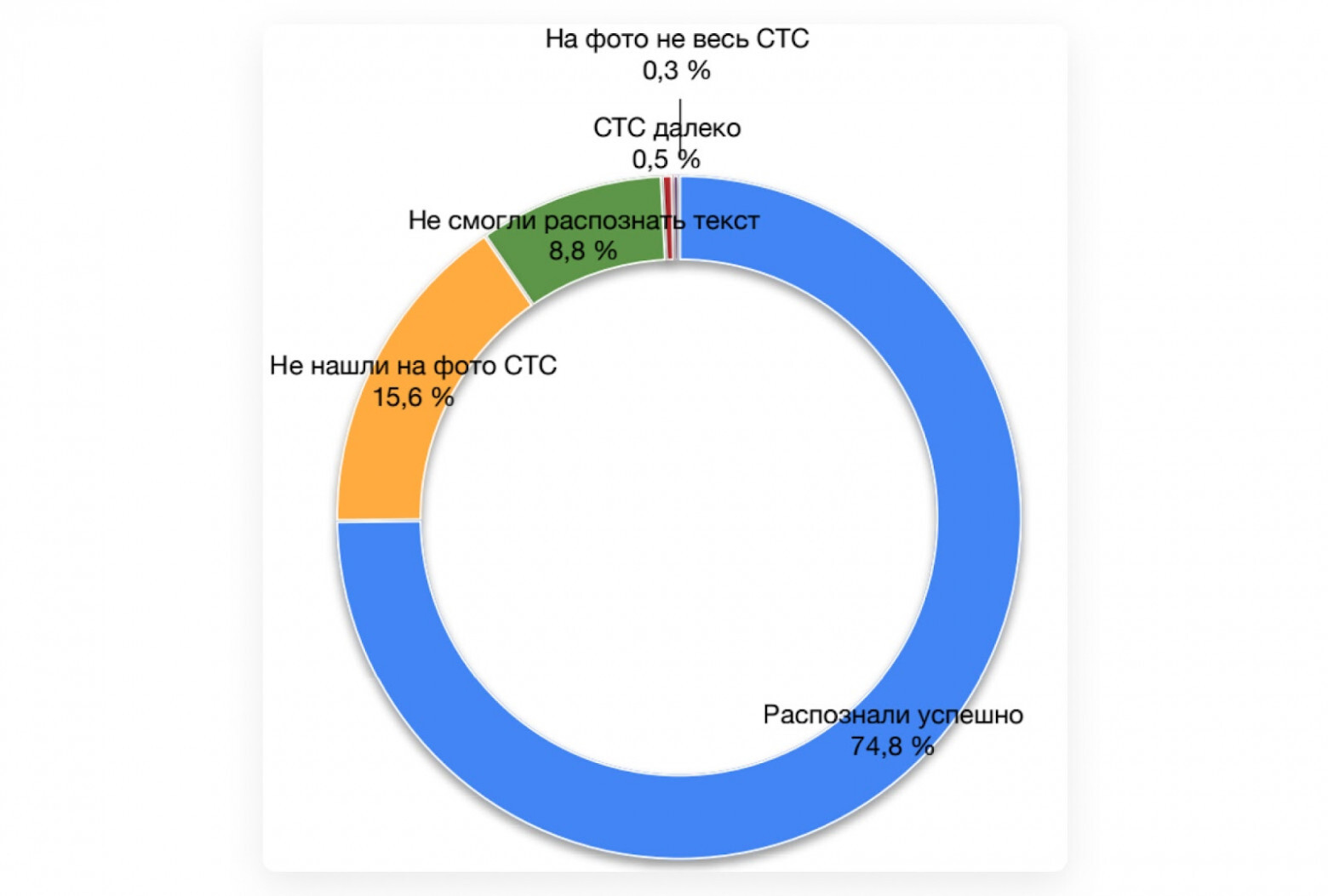
График с данными об ошибках модели. В большинстве случаев модель распознавала данные успешно
Улучшили целевые метрики:
- повысили конверсию в публикацию объявления на 4%;
- снизили количество отказов в публикации объявлений из-за неверного номера на 55%;
- уменьшили количество обращений в поддержку на 45%.
Вместо выводов: что даёт декомпозиция
В работе над этим проектом мы использовали её дважды.
Первый раз на этапе разметки — делили большую задачу по разметке со сложным контролем качества на подзадачи для асессоров. Чтобы датасет был более качественным, и мы смогли отобрать только самые подходящие примеры для обучения модели.
Второй раз, когда разбили задачу «распознать номер с документа» на несколько этапов и сделали отдельную модель для каждой стадии.
Вот что нам это дало:
Качество. Система становится качественнее, так как каждый шаг подготавливает данные для следующего. На каждом отдельном этапе решается узкая задача, и у нас появляется больше контроля.
В итоге мы можем использовать полученные данные либо при подготовке к распознаванию, либо чтобы возвращать фотографию пользователям на доработки.
Контролируемость. Отдельные шаги пайплайна проще проверять на качество, чем огромную модель, которая занимается сразу всем.
Интерпретируемость. Пайплайн с детализацией по шагам позволяет логировать промежуточные результаты и исследовать, где возникла проблема.
Гибкость. В зависимости от потребности можно настраивать отдельные шаги и не трогать весь пайплайн — например, докручивать детектор или добавлять новые параметры в проверочную модель.
Переносимость. Модели в пайплайне обучены под СТС, но ту же технологию можно применить для других документов — например, для кадастровых номеров в объявлениях о продаже недвижимости.
Масштабируемость. Адаптироваться к продовой нагрузке проще, если есть возможность настроить ресурсы на отдельные шаги.
Спасибо вам за уделенное статье время! На вопросы буду рада ответить в комментариях к статье.
Больше интересных кейсов и историй из мира Data Science в Авито читайте в нашем не душном, а душевном телеграм-канале — «Доска AI объявлений». Подробнее о том, какие задачи решают инженеры Авито и с помощью каких инструментов они это делают — на нашем сайте и в телеграм-канале AvitoTech. Свежие вакансии в нашу команду — вот здесь.
