




Привет! Меня зовут Влад Божьев, я старший разработчик юнита АБ-тестирования Авито. В нашей команде мы ежедневно работаем с по-настоящему большими объёмами данных – это не просто фигура речи, это наша реальность. Мы помогаем создавать метрики, которые помогают бизнесу не «гадать на кофейной гуще», а принимать взвешенные решения, основанные на данных.

Один из наших ключевых инструментов – M42, сервис для визуализации метрик. Он позволяет быстро проверять гипотезы, анализировать отклонения и оценивать инициативы. M42 – это часть единого аналитического продукта Trisigma, вторая его половина – платформа для A/B-тестирования. Trisigma считает и визуализирует метрики в конкретных A/B-экспериментах, а M42 помогает принимать решения глобально по продукту. Видео с подробным разбором продукта и его возможностей:
В этой статье мы с вами погружаемся в самое сердце M42 и разбираем, как же там хранятся отчеты по метрикам. Это не просто рассказ, это почти детективная история о том, как мы искали оптимальное решение.
В нашем семантическом слое данных больше 20 000 метрик, и есть десятки разрезов для каждой из них. В этой статье рассказываю, как мы храним терабайты данных и автоматизируем добавление новых разрезов в отчёт M42.
M42: инструмент для метрик, гипотез и ответа на главный вопрос вселенной
Начнем с контекста. Почему вообще решили разработать этот сервис? Основная проблема — высокая загрузка аналитиков и низкий уровень self-service. Зачастую бизнес принимает решения на основе ad-hoc запросов к аналитикам и тут возникает несколько проблем.
Проблемы для бизнеса:
- ad-hoc задачи не вмещаются в спринты аналитиков;
- ожидание выполнения ad-hoc запроса вынуждает откладывать задачи -> снижается скорость принятия решений;
- готовый дашборд нужно искать или ждать изготовление с нуля;
- готовые дашборды — это не слишком гибкое решение.
Проблемы для аналитиков:
- они перегружены ad-hoc: не хватает времени на исследовательские задачи;
- много рутины: выгрузка одних и тех же SQL с новыми JOIN;
- создают «одноразовые» дашборды и выгрузки.
Поняли, что круто организовать пользователям возможность самим создавать разрезы данных и, таким образом, минимизировать участие аналитиков в этой цепочке задач.

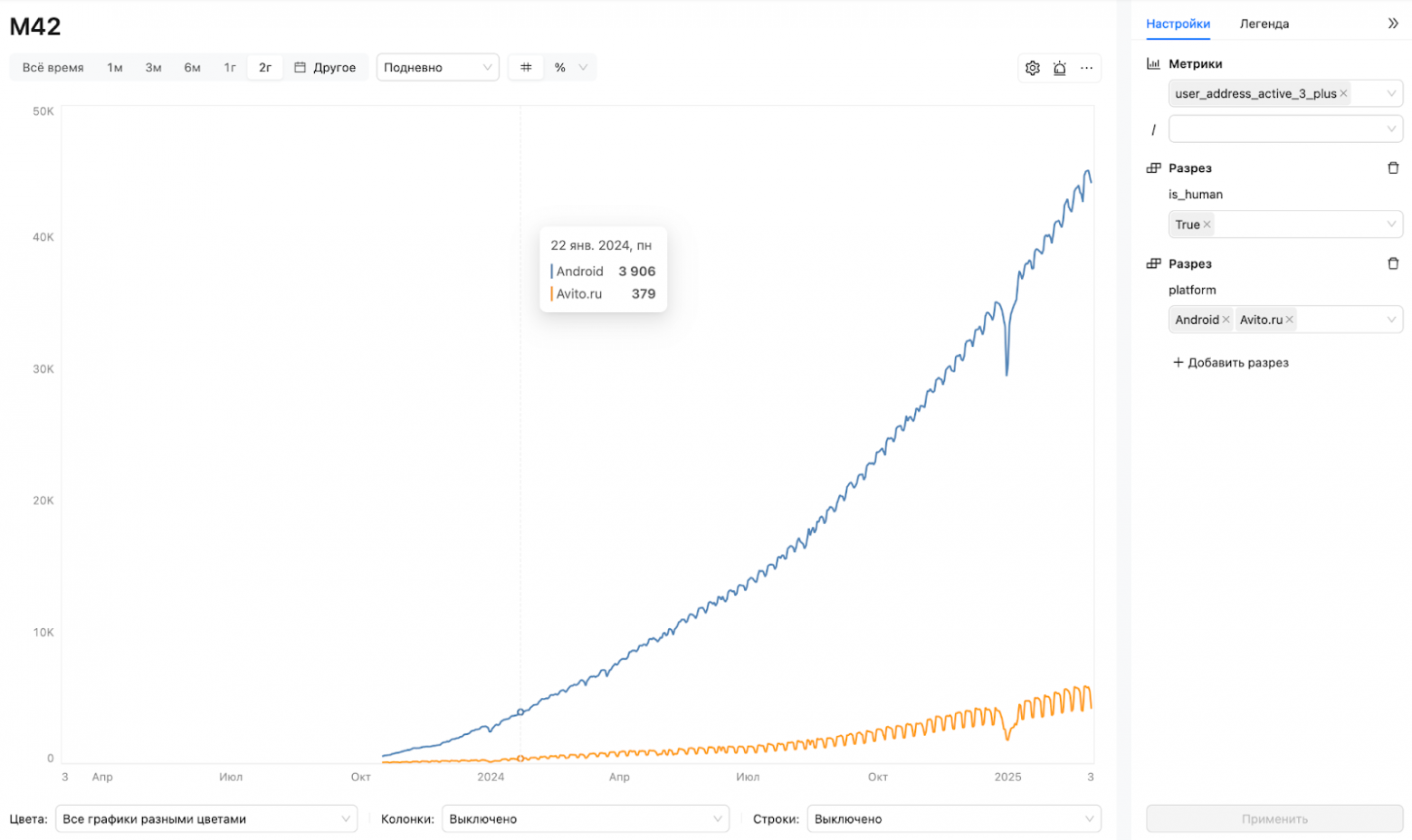
Что такое M42? Это инструмент для визуализации метрик, созданный командой Авито с помощью Trino, Clickhouse и SQL-магии, обёрнутой в SPA (Single Page Application). Можно, например, посмотреть количество кликов на рекламу, метрику рекламной выручки и выяснить прочие интересные подробности. По факту, основные задачи инструмента – это анализ и визуализация метрик, формирование гипотез, оценка потенциала инициатив компании.
Кому полезен такой инструмент? Компаниям, которые работают с метриками и принимают решения на основе данных, а конкретно таким специалистам, как продакты, маркетологи, менеджеры и аналитики. Не нужно уметь в SQL и понимать, как устроен DWH, чтобы получить нужную аналитику. Плюс в том, что специалист перестает быть ограниченным готовыми выгрузками от аналитиков.
Теперь разберемся, какие есть возможности у пользователя в М42. Он может:
- рассчитать потенциал своей идеи;
- найти причины отклонений своих метрик;
- посмотреть динамику метрик других команд и сравнить;
- перепроверить отчет;
- и делать много чего еще, подробнее рассказываю ниже.
Теперь вкратце разберем алгоритм работы пользователя в М42:
1) Аналитик создает ключевые сущности в конфигурациях в yaml-формате: источники метрик, сами метрики и разрезы.
2) Далее настраивает, какие метрики в каких разрезах считать, – по сути создает yaml-конфиг отчета.
3) Теперь любой бизнес-юзер получает регулярно обновляющийся отчет с возможностью просмотра результатов с гибкой системой фильтров по разрезам.
А еще тут возникает естественный вопрос – почему сервис называется M42? Все просто: M – это метрики, а 42 – ответ на «главный вопрос жизни, вселенной и вообще» из «Автостопом по галактике»
Проектируем таблицы M42
Что имеем
Теперь самое интересное – давайте попробуем вместе разработать оптимальный способ хранения отчётов M42. Сразу оговорюсь, мы коснемся процесса расчёта M42 лишь вскользь, потому что это тема для отдельной, не менее увлекательной статьи, а сегодня сосредоточимся именно на хранении данных. Следите за обновлениями, как говорится ;)
Но прежде разберемся, какие вводные у нас есть:

Есть Clickstream — это внутренний инструмент для сбора пользовательской активности. На основе этих данных мы и строим метрики.
Слой витрин представляет собой регулярно обновляемые таблицы, которые агрегируют сырые данные из Clickstream и других источников.
Семантический слой – представляет собой набор базовых сущностей: источники метрик, сами метрики, разрезы и прочие, из них строится вся комплексная аналитика в A/B и M42.
Семантический слой формирует регулярный SQL, который считается на движке Trino, и результатом которого являются отчёты по A/B и M42.
Затем отчёты выгружаются в Clickhouse для быстрого чтения и отображаются в UI SPA Trisigma.
Ключевое требование к системе – наличие возможности гибко настраивать разрезы по различным параметрам, в которых нам интересна конкретная метрика. При этом количество таких параметров (мы их называем дименшенами или измерениями) может составлять десятки, а у каждого из них – сотни, тысячи, а то и сотни тысяч уникальных значений (например, ID рекламных кампаний).
Так, мы можем фильтровать данные по регионам и/или по конкретным вертикалям бизнеса, чтобы оценить, как они влияют на те или иные показатели.

Такой подход даёт нам возможность проводить глубинный анализ и видеть картину не в «средних» цифрах, а в деталях, что важно для принятия решений.
Прорабатываем реализацию
Давайте подумаем над возможной реализацией такой системы:
Как гласит один из ключевых принципов проектирования – KISS (Keep It Simple, Stupid) – не усложняй без необходимости.
Раз у нас все сырые данные для расчёта уже хранятся в таблицах фактов (в DWH), то, может, мы можем попробовать рассчитывать отчёт на лету? То есть, пользователь в M42 выбирает метрику, нужные разрезы, период, нажимает «показать», и в этот момент летит запрос в Trino, который считает все из DWH. Затрагиваем только запрошенные пользователем разрезы и метрики. Звучит просто и элегантно, не правда ли?
Но будет ли такой запрос выполняться достаточно быстро? Давайте прикинем.
В ключевом источнике данных Авито, нашем Clickstream, за один месяц накапливается примерно 45 миллиардов строк. А наиболее частый сценарий просмотра метрики в M42 – это просмотр временного ряда за 3 месяца, а то и за год.
Получается, что наш запрос «на лету» должен будет обрабатывать десятки, а то и сотни миллиардов строк! И это не просто SELECT, это запросы с группировками (GROUP BY), агрегациями (SUM, COUNT DISTINCT, AVG), соединениями (JOIN).
На наших данных даже запрос по относительно небольшому числу слайсов (комбинаций разрезов) будет работать часы (или вовсе не поместится в память и упадет). Пользователь просто не будет ждать минуты, не говоря уже о часах. Это абсолютно неприемлемо для UX. Нужен отклик в пределах секунд.
Хорошо, скажете вы, а что если внедрить слой кеширования? Будем предрассчитывать наиболее востребованные комбинации фильтров по разрезам и складывать куда-нибудь, откуда их можно быстро достать (aka cache ahead). Давайте попробуем оценить, какое количество комбинаций нам пришлось бы кешировать для приемлемой отзывчивости.
В нашем семантическом слое около 250 различных разрезов. У каждого из них – от десятков до тысяч, а иногда и сотен тысяч уникальных значений. Если попытаться посчитать все возможные комбинации даже для небольшого подмножества разрезов, цифра получится астрономической. Формула для числа комбинаций N_comb = V1 V2 ... * Vk (где Vi – количество значений у i-го разреза, а K – количество выбранных разрезов) дает нам это понять.
Но помним, что смысл кеширующих слоев в движках семантических слоев – это кешировать не всё на свете, а только самое популярное. Однако даже если мы ограничимся только самые популярные комбинации значений, то на реальных данных это все равно будут многие миллиарды комбинаций.
Такое количество уникальных фильтров потребовало бы построения крайне сложной и требовательной к ресурсам системы кеширования. И все равно вероятность «промаха мимо кеша» была бы очень высока. А промах – это снова ожидание отчета, исчисляемое часами.
Получается, что решение с подсчётом на лету, даже с продвинутым кешированием, не выглядит ни простым, ни дешевым в плане ресурсов. Мы неизбежно упираемся в необходимость заранее рассчитывать метрики в большом количестве комбинаций разрезов. Да, для небольшой компании вариант с кешом и расчетом на лету вполне работоспособен. Но для Авито с его масштабами и других бигтех-компаний такой способ точно не подходит.
Время ответа ручки API, которая отдает данные для отчета, должно быть очень маленьким, иначе UI M42 будет «тормозить» и вызывать раздражение. Часы ожидания тут точно не про нас.
Добавляем промежуточный предрасчет отчёта M42
Значит, нам необходимо создать промежуточный регулярный расчет. Иными словами, мы будем заранее, например, раз в день, считать все необходимые комбинации метрик и разрезов и складывать их в какую-то витрину, оптимизированную для быстрого чтения. При этом важно понимать что в систему будут постоянно добавляться новые разрезы и их значения, а значит наша система хранения должна уметь легко расширять их набор.
Мы принимаем день как минимальную единицу расчета. Это означает, что пользователь сможет просматривать полные данные без дальнейших мутаций отчёта с задержкой в один день (то есть сегодня он видит данные «за вчера»). Для большинства аналитических задач такой гранулярности и свежести вполне достаточно.
Итак, мы решили, что данные нужно предрассчитывать. Теперь вопрос – как их структурировать?
Давайте попробуем ввести структуру для хранения комбинаций: введем понятие слайса (slice). Пусть слайс – это конкретная комбинация значений выбранных измерений (дименшенов). Например, (region='Москва', category='Авто', platform='Android') – это один слайс. Мы можем каждой такой уникальной комбинации назначить свой числовой идентификатор (slice_id). Для этого можно вести отдельную таблицу-справочник: slices (slice_id UInt, dimension1_value, dimension2_value, ...) или, как вариант, slices (slice_id UInt, slice_definition JSON).
Это будет выглядеть примерно так:
CREATE TABLE db.slices(slice_id UInt64,slice_definition JSON)
Идея с JSON выглядит заманчиво: slice_definition мог бы хранить что-то вроде {"region": "Москва", "category_id": 123, "platform": "Android"}. Это позволит легко расширять набор разрезов в отчёте M42, не изменяя структуру таблицы фактов (где будут храниться сами метрики), ведь там будет просто slice_id.
Однако нужно помнить, что фильтрация по значениям дименшенов – это ключевая возможность M42
Пользователи будут постоянно хотеть отфильтровать отчет по Москве или по Android. Значит, нам нужно убедиться, что такая фильтрация по содержимому JSON будет работать эффективно.
Давайте снова посчитаем. Как мы уже выяснили выше – у дименшенов могут быть миллиарды комбинаций. Если мы хотим по ним эффективно фильтровать, нам нужно будет их все загрузить в нашу гипотетическую таблицу slices (slice_id, slice_definition JSON) для дальнейшего использования при построении отчетов.
Поскольку мы планируем активно читать и фильтровать по этой таблице слайсов, нам нужно обеспечить быстрое чтение. Но вот беда: фильтрация по содержимому JSON-поля в большинстве СУБД (включая ClickHouse) – операция крайне неэффективная, даже если JSON не очень большой. ClickHouse, конечно, умеет работать с JSON, но это не его основная сильная сторона для фильтрации больших объемов.
Значит, нам понадобятся индексы. А как индексировать JSON? В ClickHouse для этого можно создать MATERIALIZED колонки для каждого дименшена, извлекая значения из JSON (JSONExtractString(slice_definition, 'region') AS region_name_materialized), и уже на эти материализованные колонки «вешать» индексы.
Давайте взвесим риски хранения комбинаций разрезов в JSON формате в этой таблице-справочнике слайсов:
- Дублирование данных и размер. Хотя нам доступны индексы через материализованные колонки, такой индекс требует существенного дублирования данных. Во-первых, сама материализованная колонка – это уже копия данных из JSON. Во-вторых, сам индекс тоже занимает место. При учёте, что там будет храниться от 20 миллиардов строк (если мы решим материализовать все возможные комбинации, что, как мы помним, очень много), такая таблица slices будет занимать терабайты дискового пространства даже без учёта индексов. Размер таблицы здесь действительно имеет значение, при этом используя json колонку не получится применить колоночное сжатие эффективно, так как Clickhouse не сможет применить сортировку по колонкам перед сжатием.
- Сложность и производительность запросов. Запросы к таблице со слайсами для фильтрации потребуют применения конструкций типа JSONExtract... (если мы не используем материализованные колонки для всех полей, по которым можем фильтровать, что маловероятно). Это существенно снижает читабельность SQL и может быть медленнее, чем прямая фильтрация по типизированной колонке.
- Обновления и вставки. По мере развития платформы органически будут появляться новые комбинации значений дименшенов (например, новый город или новая категория). Их потребуется вставить в таблицу со слайсами. Однако операции вставки будут существенно замедлены необходимостью обновлять материализованные колонки и их индексы.
- Избыточность JSON. Сам формат JSON достаточно многословен. Имена ключей ("region", "category_id") повторяются в каждой строке (если мы храним JSON для каждой комбинации). Это требует больше места для хранения, чем если бы значения дименшенов хранились в отдельных типизированных колонках.
Таким образом, конструкция с JSON-хранением слайсов в таблице-справочнике несет много накладных расходов, потенциально медленная и не позволит строить простые для анализа запросы. Давайте проанализируем другие опции.
А что, если мы разделим слайс на отдельные колонки под каждый дименшен в этой таблице-справочнике? То есть, вместо slices (slice_id, slice_json) у нас будет slice_definitions (slice_id, region_id, category_id, platform_id, ...)? Это, кажется, как раз то, что «доктор прописал» для справочника комбинаций!
Давайте прикинем, что нам это даст:
Фильтрация. Она станет просто молниеносной по сравнению с JSON. Ведь фильтровать по конкретной колонке с нативным типом данных (WHERE region_id = 123) – это стандартная, хорошо оптимизированная операция для любой СУБД, и ClickHouse тут не исключение. Никаких JSONExtract, просто WHERE dimension_X = 'value'. Красота! И индексы по таким колонкам будут работать как часы, без всяких там «материализованных костылей» для JSON.
Размер хранимых данных. Мы сразу избавляемся от многословности JSON. Каждое значение будет храниться в своем оптимальном формате. Если какой-то дименшен имеет, скажем, всего 250 уникальных значений (например, коды стран), его можно уложить в UInt8 (или даже Enum, если СУБД поддерживает и это эффективно для такого количества), а не таскать строковое представление в JSON.
Это колоссальная экономия места, особенно на наших потенциальных миллиардах строк уникальных комбинаций. Плюс, нам больше не нужны те самые материализованные колонки для индексов, так как индексы будут строиться прямо по основным данным дименшенов. Это ещё минус дублирование и экономия терабайтов.
Читабельность и простота запросов. SQL-запросы станут не только быстрее, но и гораздо чище и понятнее. Коллегам-аналитикам (и нам самим через полгода) будет проще разбираться в логике и писать новые аналитические выборки, не ломая голову над конструкциями для извлечения данных из JSON.
Операции вставки и обновления. Добавление новых комбинаций дименшенов (а они, как мы понимаем, будут появляться) не будет вызывать такой головной боли с перестройкой громоздких материализованных JSON-атрибутов и их индексов. Обновление индексов по обычным, атомарным колонкам происходит гораздо эффективнее и быстрее.
Таким образом, каждая строка в такой таблице-справочнике slice_definitions будет максимально «легкой», и операции с ней будут быстрыми. Мы получаем прозрачную структуру, предсказуемую производительность и возможность гибко работать с данными, не упираясь в ограничения JSON-парсинга на лету или сложности с материализованными представлениями.
По сути, мы возвращаемся к классическому, проверенному временем реляционному подходу там, где он действительно «сияет» – в эффективной обработке и фильтрации структурированных данных. Да, нам придется перечислить все дименшены как отдельные колонки в таблице slice_definitions, и если появится совершенно новый тип дименшена (например, «тип браузера»), нам нужно будет добавить новую колонку в эту таблицу (ALTER TABLE slice_definitions ADD COLUMN browser_id ...). Но выигрыш в производительности, экономии места и простоте обслуживания, на мой взгляд, с лихвой перекрывает это «неудобство».
Вторую часть статьи можно прочитать здесь.
