




Привет, Хабр! Меня зовут Игорь Балюк, совсем недавно я работал платформенным инженером в Авито, разрабатывал «магическую коробочку», которая автоматизирует всю рутину, связанную с созданием сервиса. А еще я следил за тем, как эти сервисы друг с другом общаются и как далее они эксплуатируются.
Продуктовые разработчики Авито, как правило, думают именно о том, как написать классный продуктовый код, который отражает бизнес-логику, а всю неинтересную для них инфраструктурную рутину мы забираем на себя. В платформе я занимался двумя вещам: сбором телеметрии (логи, трейсинг и так далее) и Service Mesh.
В этой статье я рассказываю про второй аспект моей работы, Service Mesh, и показываю, что это, скорее, не конечная точка, где можно найти «серебряную пулю» от всех проблем, а путь, который, возможно, никогда не закончится: придется постоянно куда-то бежать и что-то дорабатывать. В статье я также разбираю, как работает Service Mesh в Авито.
Посмотреть выступление с докладом по этой теме также можно посмотреть здесь.

Service Mesh — дорога, а не пункт назначения
Давайте обратимся к названию. В словосочетании Service Mesh есть слово «сервис». Наверняка, истоки восходят к каким-то сервисам.

В какой-то момент в больших компаниях число сервисов бурно возросло, с чем столкнулись и мы. Поэтому потребовался подход, способствующий организации сервисного общения.
Сегодня под Service Mesh подразумевается некоторый фреймворк, который и позволяет наладить это межсервисное общение.
При этом мы хотим сделать так, чтобы межсервисное общение было:
- гибким и управляемым, чтобы мы как администраторы могли все быстро подкрутить, чтобы трафик балансировался между разными дата-центрами и так далее;
- наблюдаемым: сверху можно посмотреть на всю систему, получить автоматические метрики, лучше реализовать трейсинг — как наши сервисы друг с другом связаны, какие взаимоотношения у них есть;
- безопасным. Этот трек особенно популярен в последнее время. Хочется сделать так, чтобы наши сервисы общались друг с другом по безопасным протоколам, которые не позволили бы злоумышленнику при его появлении получить информацию.
Service Mesh в Авито: как мы меняли решения
В Авито мы реализуем Service Mesh более шести лет. Сейчас у нас:
- 4 500 уникальных сервисов;
- 2 250 сотрудников в разработке;
- более 1 млн запросов в секунду, проходящих через Service Mesh;
- есть инсталляции с инфраструктурой как on-prem, так и в облаке.

Платформа Авито начала зарождаться в 2018 году. Уже тогда у нас было довольно много (около 150) сервисов, поэтому захотелось протестировать какой-нибудь Service Mesh. Начинать стоит с чего-то простого — так и появился наш первый велосипед Netra.
В течение года мы опробовали гипотезу, что Service Mesh — это, в принципе, классное направление, куда нам хочется идти. Поэтому один велосипед мы заменили на второй и назвали его Navigator. С ним мы прожили еще несколько лет до конца 2022 года. За это время к нам прилетали все новые и новые требования от бизнеса.
К концу 2022 года нам надоело делать свои велосипеды, мы попробовали пойти в комьюнити и посмотреть, что существует уже в готовом виде, — так мы обратились к Istio.
Давайте начнем сначала.
2018 год. Мы хотим проверить гипотезу и начать с чего-то очень простого, поэтому решаем построить карту сервисного общения. Каких-то строгих требований к тому, какой Service Mesh хочется взять, у нас не было.
Типичный Service Mesh на тот момент выглядел следующим образом:

Есть Control Plane — специальный компонент, который наблюдает за всей системой. Есть специальная sidecar-прокси, которая подселяется в каждый Kubernetes-под и контролирует весь входящий и исходящий трафик, может с ним что-то делать: например, отправлять его в другое место.
При этом на тот момент уже были такие решения, как Istio и linkerd.

Мы решили, что они для нас слишком сырые и неудовлетворительные по перформансу и потреблению ресурсов, ведь мы просто хотим проверить гипотезу. Начинать стоит с чего-то простого, так и появилась та самая netra — реализация нашей собственной proxy, написанная на Go.

Netra представляла собой легковесное решение (<2000 строк Go-кода) без Control Plane. Данная sidecar-прокси прозрачно обрабатывала весь входящий и исходящий трафик из приложения, автоматически собирала метрики и трейсы и обеспечивала базовую маршрутизацию.
Ускорение тестирование за счет sidecar-прокси

Контроль версий за счет заголовка X-Route
Представьте, что у нас много сервисов и разработчиков. Одновременно несколько разработчиков хотят разрабатывать один и тот же сервис — обновить его код, выкатить свои изменения и проверить их в определенном staging окружении. Когда людей становится много, начинается толкание локтями. Нужно либо договариваться о каком-то расписании, мол «я беру сервис с двух до трех часов дня, пожалуйста, не мешайте», либо иметь много изолированных staging окружений, чтобы каждый нашел себе место, где можно что-то протестировать. Данный подход плохо масштабируется с ростом компании.
Поэтому мы пришли к идее так называемых «изолированных веток». Представьте, что мы хотим выкатить новую версию сервиса. Делаем изменения в git, выкатываем изолированную версию сервиса, которая существует параллельно основной версии сервиса. По умолчанию все запросы идут на основную версию сервиса. Но если мы укажем некий специальный HTTP-заголовок X-Route, то proxy увидит этот заголовок и поймет, что запрос нужно отправить не на основную версию сервиса, а на одну из его «веток».
Возможности netra
Благодаря простому решению в 2000 строк кода мы:
- получили наблюдаемость системы (метрики, трейсинг);
- улучшили тестирование и ускорили TTM.
Но осталось очень много вопросов, которые netra не покрывала:
- нет service discovery;
- нет гибкого управления: мы никак не можем управлять трафиком, потому что нет Control Plane;
- непонятно, как быть с межкластерными походами. Клиенту по-прежнему нужно знать, где именно запущенные зависимости, к которым он хочет обращаться;
- не продвинулись в направлении безопасности.
В поисках нового Service Mesh: Navigator
Сама идея Service Mesh нам очень понравилась. В 2019 году мы всё же попробовали запустить Istio в нашей инфраструктуре, но обнаружили проблемы с производительностью: накладные расходы на ресурсы выходили довольно высокими. Это было связано с архитектурой на Istio. На тот момент сайдкары знали про все остальные сайдкары в системе, из-за чего конфиг у envoy-сайдкара сильно распухал и требовал много RAM. При этом Istio не давал хорошего решения для упрощения межкластерных запросов.
Тогда мы решили, что Istio, хотя и многообещающий инструмент, пока все же сыроват, а потому сделали еще один велосипед. На тот момент вдохновились ingress-контроллером Project Contour. Так появился еще один Service Mesh – Navigator.

Navigator представляет из себя тот самый Control Plane, который обращается к API Kubernetes, получает информацию про поды и ресурсы, необходимые для конфигурации, и готовит конфигурацию для envoy. envoy — это уже реализованная прокси, которая будет запущена в каждом поде рядом с настоящим приложением в роли сайдкара.
Имея Control Plane, довольно легко получилось реализовать Service Discovery: navigator явно знает, когда в системе появляются новые поды, когда эти поды становятся недоступными, а также в каких кластерах и дата-центрах они запущены.
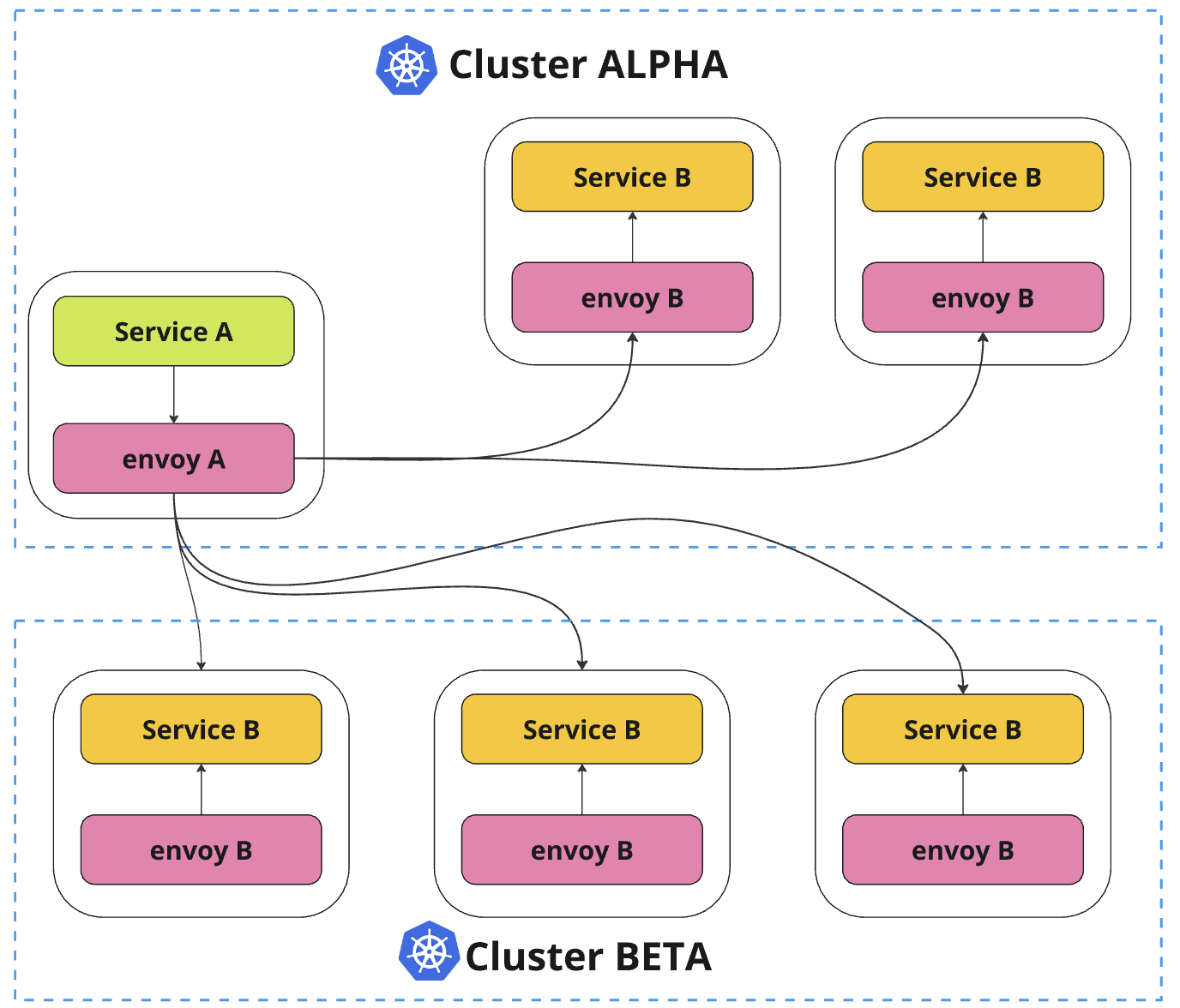
Service Discovery
За счет этого мы можем сильно упростить логику и код клиента, потому что клиенту теперь достаточно сказать: «я хочу подключиться к какому-то сервису X», а дальше уже envoy проксирует этот запрос и знает, в каких кластерах запущен тот самый сервис X. envoy позволяет настроить «умную» балансировку трафика и будет учитывать локальность, что позволит оптимизировать latency.
Далее мы перешли к идее канареечных релизов (canary rollout / release).
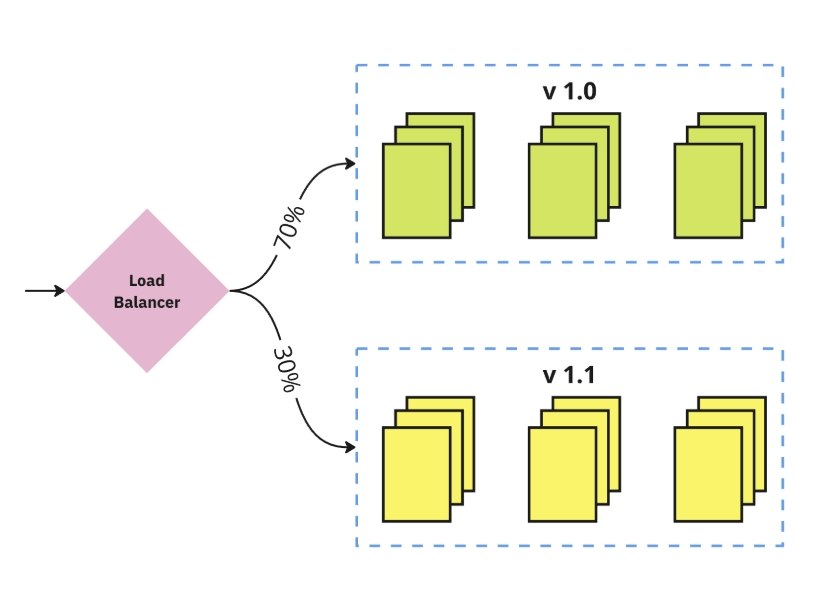
Canary Release: разделяем трафик между старой и новой версиями и снижаем урон от релиза с багами
Когда разработчик хочет выпустить новую версию своего приложения, мы запускаем ее параллельно основной и начинаем постепенно подавать трафик на новую версию приложения: сначала 10% трафика, потом 15%, 20% и так далее. Если по метрикам все хорошо, докатываем «канарейку» до 100%. Если по метрикам видим, что появились какие-то новые «пятисотки» либо у новой версии увеличился латенси, «канарейка» отменяется, пока не будет найдена причина. Данные релизы позволяют значительно снизить урон от багов, которые сложно отловить на этапе тестирования и staging окружении.
С точки зрения конфигурации Navigator был довольно простым.
Для конфигурации использовались стандартные ресурсы из Kubernetes — Service и Ingress, которые регистрировали сущность сервиса в нашей системе и управляли внешней подачей трафика.
Наши собственные ресурсы — это Canary, который банально контролировал, какой процент канарейки нужно пустить на новую версию приложения, и Nexus.
apiVersion: v1items:- apiVersion: navigator.avito.ru/v1kind: Nexusmetadata:...spec:appName: cars-service-catalog-2119-stagingcookieAffinity: ""downstreams:- name: cars-service-catalog-2119-stagingnamespace: cars-serviceheaderAffinity: ""inboundPorts:- name: httpport: 8890mTLS:enabled: truespiffeID: spiffe://company/hs/cars-service/service/non-prodrateLimit:enabled: falseport: 15011serviceName: cars-serviceservices:- namespace: toggles- namespace: geo-locator- namespace: image-classifier- namespace: ab-tests- namespace: delivery-layout- namespace: cars-storage- namespace: user-profile- namespace: cars-service
Nexus — еще одна наша собственная самоделка, которая содержит в себе всю необходимую нам информацию про сервис. Данный ресурс позволял контролировать параметры rate limit, управлять режимом TLS и требовал указывать список зависимостей сервиса. По сравнению с другими решениями (Istio) настраивать Service Mesh благодаря одному типу ресурса было значительно проще.
Давайте поговорим про безопасность
Первое, что хочется сделать — внедрить в систему проверенный протокол HTTPS.
Он относительно старый, но в этом его преимущество. HTTPS очень распространен. Все языки программирования и многие фреймворки уже умеют с ним работать: понятно, как подключить сертификаты в свой сервис, как научить приложение общаться по HTTPS.
Но базовый HTTPS не решает проблему доверия клиенту. Сервер не знает, кто именно к нему подключился. Для решения этой задачи существует расширение протокола TLS, которое называется Mutual TLS. Теперь сертификат будет не только у сервера, но и у клиента тоже.

Таким образом, когда сервер получает запрос от клиента, он может посмотреть на сертификат клиента, проверить, что сертификат подписан корректным сертификационным центром, и в этом сертификате написано, кто является этим клиентом.
Подобная модель, по сути, решает проблему отсутствия аутентификации.
[[policy]]description = "Ограничить доступ к РТГ данным"endpoints = ["грс:get","грс:getAll","http:put:/user/*/update","http:post/user","http:get/user/*/payments",]clients = [# сервисы"atlas","admin-api",# пользователи"user:ipivanov",# ЮНИТЫ"user.unit:paas",]
Даже если злоумышленник попадет в систему, он не сможет сделать запрос на произвольный сервис бэкенда. Для запроса необходимо получить сертификат — а его получить его могут только авторизованные сотрудники с наличием необходимых прав.
Получив аутентификацию запросов, можно перейти и к авторизации. Например, можно указать, у каких сервисов и сотрудников есть доступ к определенным HTTP-эндпоинтам для каждого сервиса.
Если интересна тема межсервисной авторизации, доклад про это можно послушать здесь.
С точки зрения инфраструктуры mTLS в Авито выглядит подобным образом:
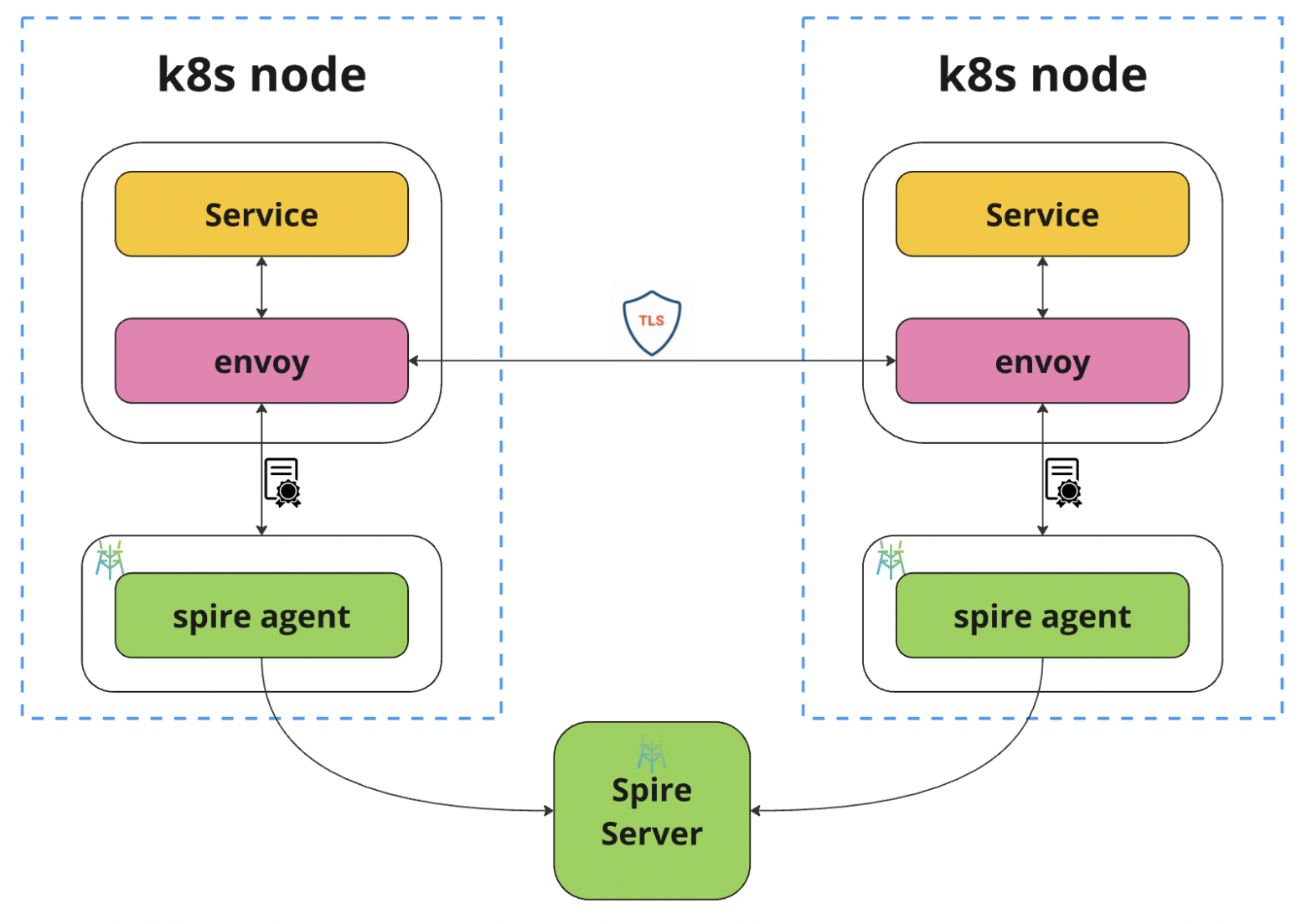
Центральным компонентом является Spire. Это готовый компонент, запущенный вне контура k8s кластера, который занимается регистрацией сущностей в системе и генерацией сертификатов для этих сущностей. При этом на каждом Kubernetes-узле запущен специальный Spire-агент. Агент является некоторым кэшом (или прокси) для основного spire сервера. И когда на Kubernetes-узле появляется очередной под с envoy-сайдкаром, envoy нужно где-то взять сертификат для себя, поэтому он обращается к Spire-агенту.
Если тема безопасности вам тоже интересна, то мы рассказывали про нее здесь.
Скорее всего идея mTLS будет очень по душе вашей Security-команде. Но внедряя данный подход на большом масштабе, можно столкнуться с некоторым сопротивлением. Естественно, разработчики и владельцы сервисов могут отказываться от внедрения mTLS. Раньше можно было сделать curl запрос из терминала, а теперь необходимо думать про сертификаты.
Для упрощения внедрения mTLS мы поддержали переходный режим, в рамках которого сервис может принимать запросы как с сертификатом, так и без. Когда мы хотим переключить определенный сервис на mTLS, мы идем по следующему алгоритму:
- разрешаем подключение к нему как с сертификатом, так и без;
- всем легитимным клиентам сервиса добавляем клиентский сертификат;
- когда все клиенты переведены, запрещаем подключение к сервису без клиентского сертификата.
Наконец-то…
После нескольких лет мы пришли довольно к очевидному выводу, что разрабатывать свои велосипеды — это не очень-то приятно и довольно сложно.
Наша команда из четырёх человек занималась поддержкой Navigator, в то время как требования к системе постоянно росли. Особую сложность представляло тестирование Service Mesh: end-to-end тесты не покрывали всего разнообразия продакшен-сценариев, что делало каждое изменение потенциально опасным — ошибка в Control Plane могла парализовать всё сервисное взаимодействие в организации. Усугубляло ситуацию отсутствие документации, осложнявшее онбординг новых сотрудников.
Вскоре появилась необходимость поддержать возможность использования облачной инфраструктуры для запуска сервисов, что потребовало существенных доработок Navigator. В итоге это привело нас к решению о переходе на Istio.
Istio: финальный босс
Попробовав два собственных решения, в конце концов мы пришли Istio по нескольким ключевым причинам:
- Совместимость: в нашей инфраструктуре уже использовались envoy-сайдкары, поэтому мы хорошо понимаем их поведение и накладные расходы.
- Зрелость: проект значительно развился — оптимизирована производительность, устранены основные ошибки. Будучи одним из самых популярных Service Mesh решений, Istio проходит проверку в тысячах производственных окружений, что минимизирует риск критических багов в стабильных версиях.
- Документация: хотя и не идеальная, она достаточно подробна для open-source проекта и позволяет проводить онбординг новых сотрудников.
- Поддержка межкластерных запросов: встроенные инструменты помогают быстро организовать общение между инфраструктурой on-premise и облаком (например, с помощью east-west gateway).
Как выглядела миграция?

Вся наша сервисная инфраструктура работала на Navigator. Рассмотрим пример сервиса A в Kubernetes:
- запущен в отдельном поде;
- содержит приложение и envoy-контейнер;
- имеет связанные Kubernetes-ресурсы для настройки сетевого взаимодействия
Над этой конструкцией располагается Navigator. Control Plane наблюдает за состоянием ресурсов и генерирует специализированную конфигурацию для envoy.
Есть другой сервис B, с которым первый сервис общается через envoy.

Приняв решение о миграции сервиса B с Navigator на Istio, мы столкнулись с необходимостью добавления в namespace множества специфичных манифестов, требуемых для работы Istio.

После подготовки валидных манифестов мы передаем namespace под управление Istio, который начинает мониторить ресурсы и генерировать конфигурацию для envoy.

При этом для владельцев приложения и для владельцев самого сервиса ничего не изменилось — envoy как общались друг с другом, так и общаются.
Как ускорить миграцию?
Не давать разработчикам доступ к манифестам :)
Нам сильно помог принцип, который был заложен в нашу платформу. В Авито у продуктовых разработчиков, как правило, нет возможности изменять k8s манифесты. Генерацией манифестов занимаются несколько специальных инфраструктурных команд. У продуктовых разработчиков есть удобный веб-интерфейс, где они настраивают работу своего сервиса под себя, однако здесь не требуется управления манифестами. Существует специальный инфраструктурный сервис, который преобразует указанные высокоуровневые параметры в YAML-конфигурации. Эту систему как раз и поддерживают несколько специализированных команд.
Istio и трудности
Шишки мы тоже набили.
Так получилось, что в Авито на момент миграции на Istio довольно сильно разнились версии Kubernetes, были продакшен-кластеры на 1.14, на 1.20, на 1.23. Когда появляется такой огромный разброс в версиях, скорее всего, возникают и некоторые несовместимости в API базовых ресурсов Kubernetes. Не получилось найти одну версию Istio, которая бы запустилась во всех кластерах одновременно.
Поэтому мы сразу же прыгаем с места в карьер и форкаем Istio так, чтобы базово научить работать как со старыми версиями ресурсов, так и с новыми.
Получается расхождение идей — мы хотели отказаться от собственных велосипедов, но как только берем готовое решение, нам приходится его копировать и патчить. К сожалению, ничего умнее на тот момент мы не придумали.
Но форкнуть может каждый. Вопрос: как этот форк дальше поддерживать? Тут нам помогает то, что Service Mesh — это не та штука, которую хочется часто обновлять.

Мы не стремимся установить каждое новое обновление Service Mesh. Обычно мы это делаем тогда, когда у нас обновляется версия Kubernetes кластеров, через пересоздание кластеров.
Действительно, каждый раз, когда мы хотим установить новую версию, необходимо пройти по всем патчам и проверить их корректность. Самих патчей не так много, поэтому данный процесс пока что контролируется.
Межкластерные походы
К сожалению, Istio не смог предоставить нам инструментов для удобной организации межкластерных походов «из коробки».
Представим, что есть три кластера, а также некий сервис, который запущен только в центральном кластере (в кластере B).

Принцип работы Istio с сервисами внутри кластера достаточно прозрачен. Полный контроль над кластером позволяет Istio обнаруживать все сервисы и автоматически анализировать взаимосвязи между ними, а также обеспечивать маршрутизацию трафика между связанными сервисами.
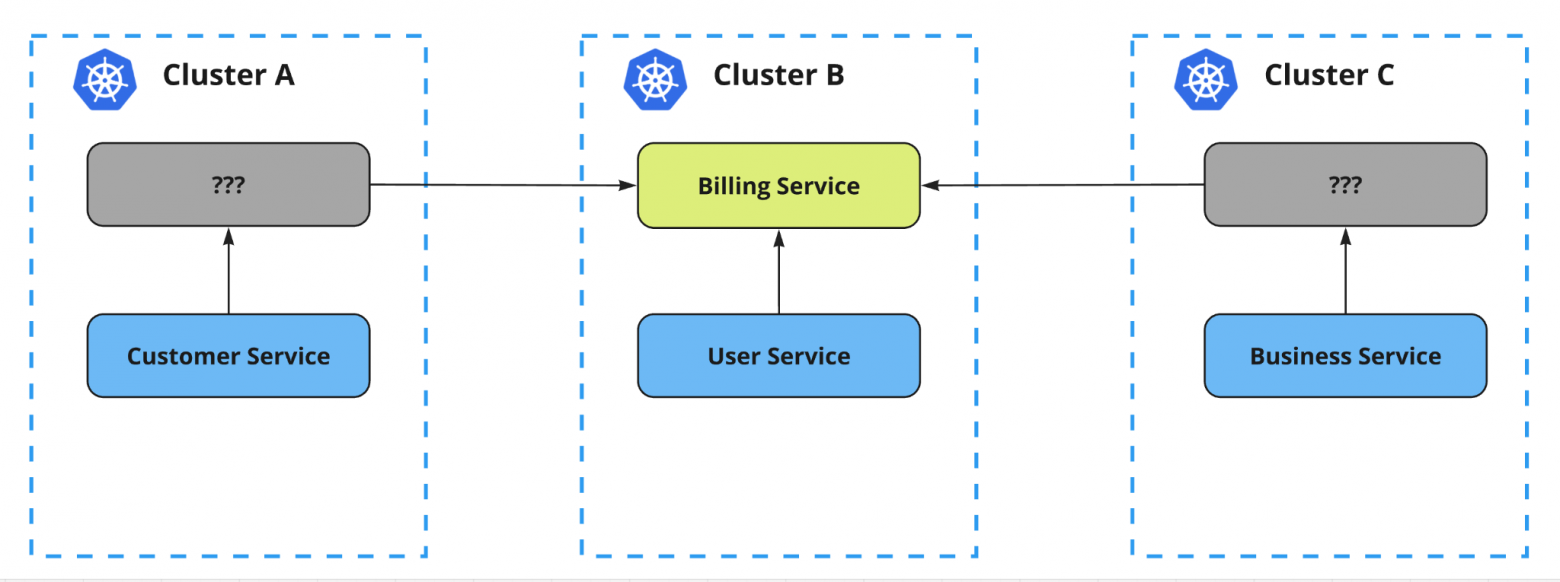
Более сложный вопрос: как организовать доступ к нашему сервису из других кластеров?
Решение лежит на поверхности: необходим механизм обнаружения, который определяет наличие сервиса в других кластерах и пробрасывает эту информацию в Istio, запущенный в локальном кластере.

Межкластерные походы: VS и DR
Чтобы это все заработало, нужно правильно настроить Istio: создать корректные манифесты и ресурсы, которые у Istio называются VirtualService и DestinationRule. Это базовые ресурсы, управляющие маршрутизацией трафика и передающие, как клиенту подключиться к серверу, какую аутентификацию использовать и так далее.
Ключевая проблема — распространение этих ресурсов в сторонние кластеры, где наш сервис не развернут. В качестве решения мы создали собственный репликатор, который занимается распространением вышеуказанных ресурсов Istio.

Ресурсы должны быть даже там, где нет deployment
Репликатор — это наш собственный оператор, запускаемый в каждом кластере. Каждый экземпляр репликатора наблюдает за всеми остальными кластерами. Если репликатор видит, что в каком-то другом кластере появился новый под сервиса или новые ресурсы DestinationRule, VirtualService, эти ресурсы копируются в локальный кластер, если их еще там нет. Таким образом, после репликации локальный Istio поймет, что есть сущность сервиса в другом кластере и настроит envoy-сайдкары своего кластера таким образом, чтобы при необходимости запросы отправлялись и в другие кластеры в том числе.
Это нас ведет к тому, что если мы начинаем сильно погружаться в Istio, то манифестов становится очень много.

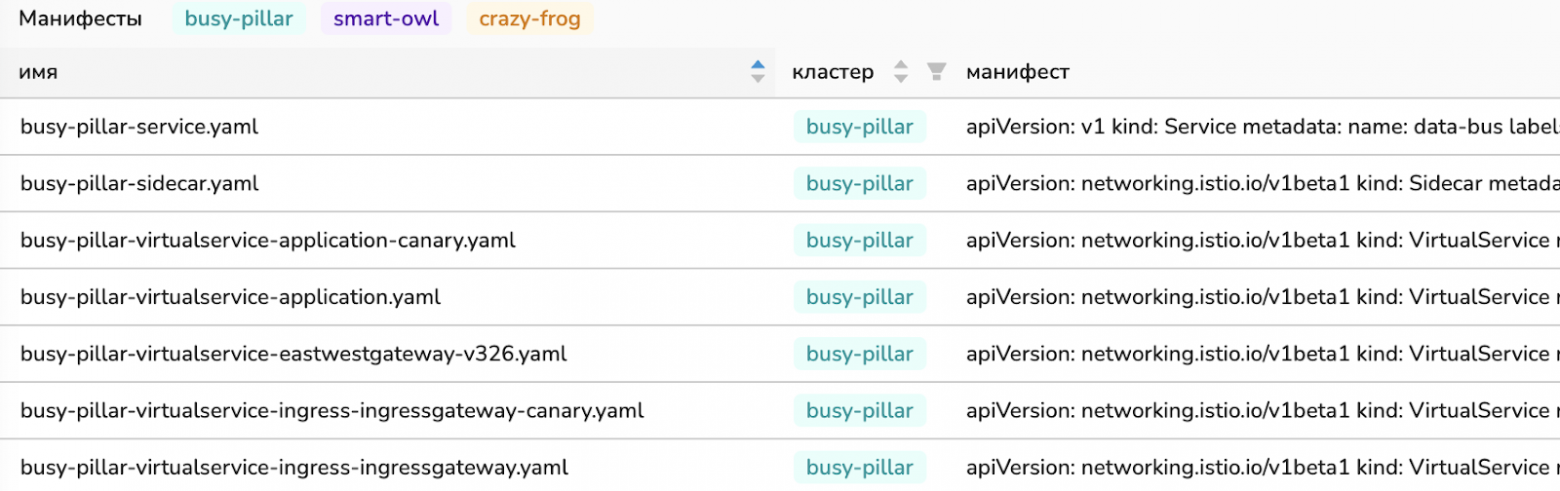
На данный момент на один деплой сервиса в один кластер мы создаем более 10 манифестов. Есть и простые манифесты, например, Peer Authentication. Но манифесты DestinationRule и VirtualService, которые нужны для основного релиза, «канарейки», East-West Gateway, ingress-контроллера и т.п., становятся очень сложными.
Чтобы лучше разобраться в этом «бардаке», у нас есть документация. На онлайн-доске распечатаны наши Kubernetes-манифесты для Istio. Между разными полями в YAML-манифестах прорисованы стрелочки, написано, что эти поля должны совпадать и быть равны друг к другу, иначе все сломается по такой-то причине.
Данная доска и ситуация, в которой мы иногда находимся, очень похожа на следующую картинку:

К сожалению, с ростом сложности Service Mesh при использовании Istio невозможно в голове одного человека уместить весь объем информации — связи становятся очень сложными.
Параллельно с этим пользователи приходят со своими вопросами.
Владельцев сервисов как правило беспокоят две проблемы:
- высокая задержка (latency);
- неожиданные ошибки (например, «upstream connect error»), которые ранее не встречались.
Как правило, на то есть две причины:
- Конфликты в конфигурации. Обычно это связано обычно с тем, что мы как владельцы Service Mesh сварили не до конца правильную конфигурацию и Istio отработал не так, как от него ожидали.
- Конфигурация распространяется долго. Если сервисов, подов, кластеров становится много, Istio может притормаживать.
Почему это важно?
Распространение обновлений
Когда мы раскатываем новую версию сервиса, у нас есть какой-то ожидаемый порядок применения наших изменений.
- Запуск новой версии приложения: для начала мы хотим дождаться готовности новой версии сервиса, приложение должно запуститься.
- Настройка mesh для новой версии: для новой версии сервиса начинаем настраивать Service Mesh, чтобы новые поды умели общаться со своими зависимостями.
- Переключение трафика: переключаем подачу трафика со старой версии приложения и на новую.
- Удаление старой версии.
Если по какой-то причине мы сначала переключим трафик, а только потом настроим Service Mesh для новой версии сервиса — конфигурация придет поздно, трафик пойдёт в бездну, т.е. в версию, которая еще не готова к эксплуатации. Istio не предоставляет какой-либо хорошей гарантии, что изменения будут применены в определенном порядке, когда речь идет про несколько ресурсов, настраивающих работу сервиса. Пока мы не реализовали хороший механизм проверки применения изменений в Istio. Вместо этого используем простой sleep с длительной задержкой в надежде, что за n секунды очередные изменения точно применятся.
Отладка Istio
Если говорить про инструменты, то для откладки Service Mesh нужно вообще всё, что у вас есть, и всё, что вы умеете:
- tcpdump;
- istioctl;
- envoy onfig_dump;
- strace, ebpf, …
Вся экспертиза в старом Linux-стеке также пригодится.
Istio и envoy предоставляют довольно много полезных метрик, но для отладки в первую очередь мы обращаемся к следующим:
- istio_requests_total — детально отражает HTTP-взаимодействия в системе и включает исчерпывающую информацию о маршрутизации (источники, назначения и другие параметры). Однако из-за чрезмерной кардинальности некоторых измерений нам пришлось исключить часть полей, чтобы сократить объем хранимых данных;
- pilot_xds_… — для диагностики задержек в работе Istio следует мониторить метрики pilot_xds_..., которые показывают время генерации конфигурации envoy и продолжительность её распространения. Высокие значения этих метрик указывают на возможную нехватку ресурсов и необходимость масштабирования Istio.
Если говорить про накладные расходы, то в каждой организации они будут разными.
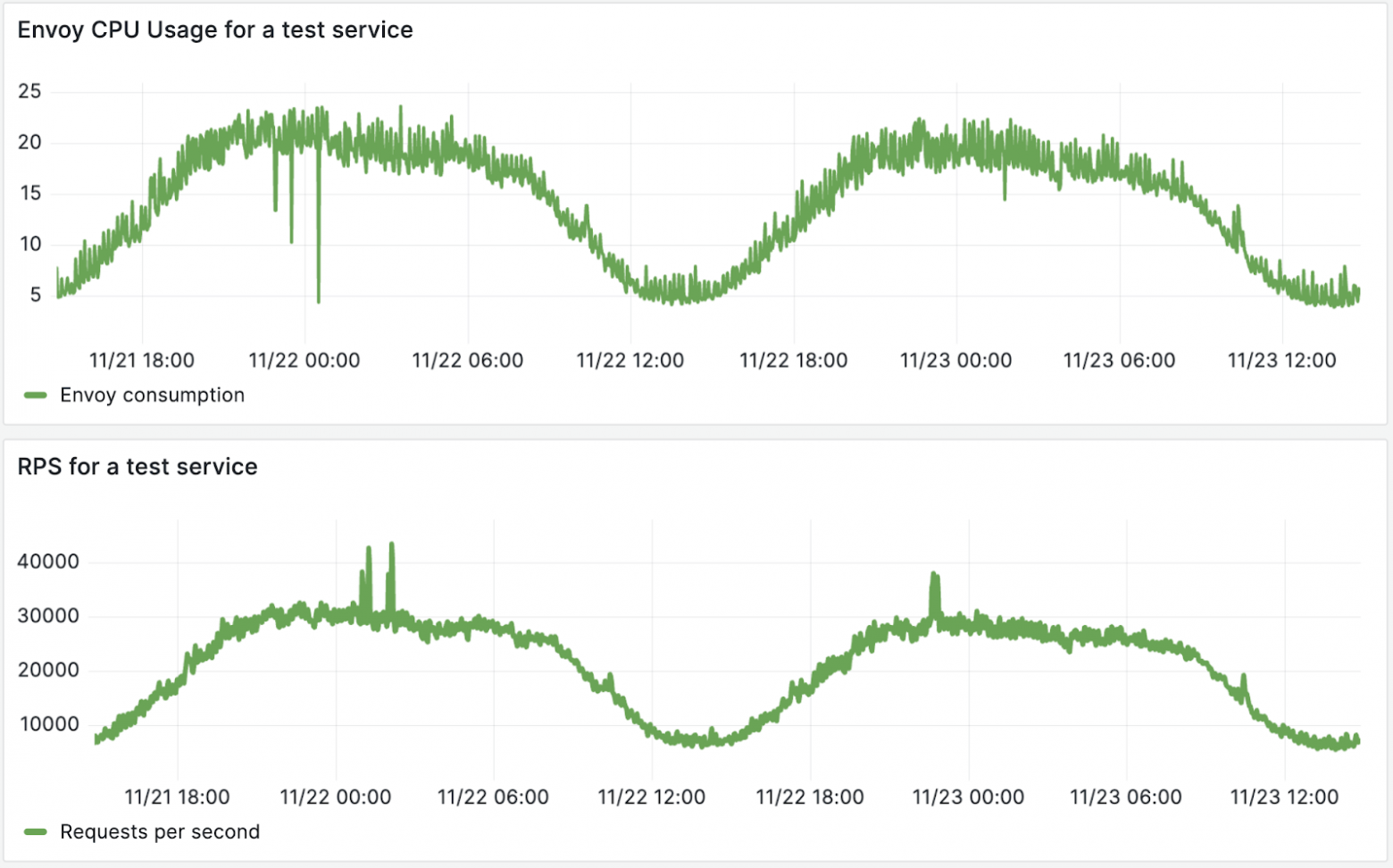
Накладные расходы:

Мы пришли к тому, что 99% потребления envoy-сайдкара у нас — это одно ядро и порядка 350MiB оперативной памяти. Но дальше можно пойти в анализ latency и посмотреть, как сильно сайдкар влияет на latency. Я не стал приводить конкретные выкладки, потому что это сильно зависит от профиля нагрузки и от того, какой именно трафик и протокол вы пускаете через этот envoy.
Istio: плюсы и минусы
От Istio мы получили следующее:
- код уже написан, не нужно слишком сильно велосипедить;
- тестируется другими, то есть критичных багов, скорее всего, не будет;
- многое есть из коробки, так как Istio пытается быть универсальным решением;
- гибкая настройка, из его готовых манифестов можно собрать целого Франкенштейна.
Но в то же время Istio:
- местами запутанный. Если наши требования слишком строгие или у владельцев сервисов много запросов, то Istio становится очень запутанным.
- реализовано многое, но не все. Несмотря на универсальность, реализовано действительно не всё. На нашем примере мы реализовывали разные репликаторы, которые помогают Istio распространять ресурсы. Есть необходимость в небольших патчах.
- напоминает о себе. Istio нельзя запустить и забыть о нем на два года. Рано или поздно что-то сломается.
Заключение
Наш опыт показал, что эксплуатация Service Mesh требует значительных усилий. Это не серебряная пуля — система сложна в настройке, подвержена сбоям и требует постоянного мониторинга определенных команд. При этом универсального решения не существует.
Мы протестировали несколько реализаций Service Mesh и остановились на Istio, хотя понимаем, что со временем выбор может измениться — возможно, появится более совершенное решение вроде Cilium++.
Тем не менее, несмотря на все сложности, Service Mesh остается мощным инструментом для организации сервисного взаимодействия.
Service Mesh — это отличный фреймворк, который нам дает те самые канареечные релизы, улучшает стабильность и отказоустойчивость нашей системы. Мы можем балансировать трафик между кластерами и сервисами, наблюдать за нашей системой автоматически без участия продуктовых разработчиков. Безопасники будут счастливы. Если говорить про подход с сайдкарами, нам неважно, на каком языке написано приложение.
Это действительно помогает организации масштабироваться. По сути, мы независимы от числа сотрудников и сервисов, которые у нас есть. Этим всем управляет лишь несколько платформенных команд.
Знаком ли вам опыт интеграции Service Mesh? Делитесь кейсами в комментариях.
А если хотите вместе с нами помогать людям и бизнесу через технологии — присоединяйтесь к командам. Свежие вакансии есть на нашем карьерном сайте.
