




Привет! Я Айрат Рахматуллин — senior аналитик в команде Seller experience (SX) Авито, мы отвечаем за опыт продавцов площадки. В этой статье рассказываю, как мы создали ML-модель, которая помогает исполнителям услуг повышать ликвидность объявлений, то есть получать больше заказов от клиентов.

Контекст: исполнители с небольшим количеством заказов уходили с площадки
На Авито пользователи могут предлагать свои услуги — от маникюра до строительства домов. Мы заметили, что среди исполнителей есть те, у кого много сделок, и те, у кого клиентов мало или нет совсем. Это чревато двумя проблемами.
Для исполнителей:
Как ни банально, но малое количество клиентов предполагает низкий доход. Для некоторых пользователей оказание услуг — это фул-тайм работа, поэтому им нужен постоянный поток заказчиков.
Для площадки Авито:
Отток пользователей. Если человеку не удаётся продать свои услуги, он может уйти с Авито и пойти пользоваться другими площадками для размещения объявлений. А когда уходят исполнители, то и заказчики тоже могут уйти с площадки, не найдя нужную услугу.
Мы решили создать инструмент, который будет помогать пользователям привлекать к своим объявлениям больше внимания и, как следствие, больше потенциальных клиентов. Расскажу, как устроена эта модель, как она работает с точки зрения пользователя, и поделюсь результатами, которые мы получили на A/B-тестах.
Коротко про модель
Чтобы не допускать оттока исполнителей и повышать ликвидность их объявлений, мы внедрили подсказки, которые помогают делать объявления продавцов более привлекательными. Для решения этой задачи мы использовали интерпретируемую ML-модель. Вот как это работает:
Выделили факторы, которые отличают продавцов с большим количеством сделок от тех, кто получает мало или не получает заказы вовсе. Например, заметили, что в категории «Ремонт техники» успехом пользуются исполнители, которые отвечают на сообщение в течение 5 минут. А мало сделок получают те, кто отвечает дольше двух часов.
В качестве таргета для обучения ML-модели использовали количество целевых контактов,то есть звонков и сообщений в чате от потенциальных заказчиков. Так как Авито работает по классифайдной модели, мы точно не знаем, привёл ли контакт к покупке. Но у нас есть аналитические выверенная метрика целевых контактов, которая очень близка к фактическому количеству сделок, поэтому мы используем её в качестве таргетной.
Проанализировали, как разные инструменты влияют на успешность исполнителя услуг. Например, скорость ответов клиентам в чате, количество фотографий в объявлении, подключение платных услуг продвижения или корректировка цены относительно рынка.
Для всех услуг одинаковые инструменты работают по-разному. Например, мастеру маникюра важнее быстро отвечать на сообщения, строителю — добавить побольше фото, а клинеру — установить цену ниже медианной. Для каждой подкатегории модель строит свою скор-карту с топом инструментов, где оценивает степень их влияния на результат.
Перевели полученные от ML-модели скор-карты в конкретные рекомендации для продавцов: что поменять в объявлении, продвижении, коммуникациях. И стали отправлять их пользователям.
Так выглядят рекомендации нашей модели в интерфейсе Авито:

Результат: А/Б-тест показал рост метрики целевых контактов — звонков и сообщений в чат. Выполняя рекомендации, исполнители получают больше сделок. Например, в подкатегории бизнес-услуг количество целевых звонков от заказчиков выросло на 13,9%.
Расскажу подробнее, как устроена модель.
Логистическая регрессия, WoE и IV: как применять на практике
Немного математики для понимания контекста.
Логистическая регрессия — это взвешенная сумма наших фичей, переведённая в вероятность. Мы берём все инструменты — они же фичи — и умножаем их на коэффициенты, которые подберёт ML-модель. А дальше видим сумму баллов, которая отражает вероятность того, что наш объект принадлежит какому-то из классов: Y=1 или Y=0.
В нашем случае есть такие классы:
Y=1 — класс, который нас интересует. Сюда входят объявления, которые получают много ликвидности.
Y=0 — противоположный класс. В нём объявления, которые получают мало ликвидности или не получают её вовсе.
И такие параметры модели:
X1, X2… — фичи, которые помогают селлерам получать больше сделок. Например, время ответа на сообщение или количество фотографий в объявлении.
w0, w1, w2… — коэффициенты, которые подбирает ML-модель.
p — вероятность, что наш объект принадлежит к классу 1.
(1-p) — вероятность, что наш объект принадлежит к классу 0.
Классическая логистическая регрессия выглядит так:

Чтобы получить вероятности принадлежности к классу, то есть предположить, что у объявления будет хорошая ликвидность, полученную сумму заводим под сигмоиду. Если число положительное — значит, наш объект с какой-то вероятностью принадлежит к классу один и использование конкретной фичи увеличивает ликвидность объявления.
В случае отрицательного числа — чем больше оно по модулю, тем меньше вероятность, что наш объект с конкретными фичами относится к классу один.
Сигмоида — монотонно возрастающая функция, которая превращает баллы в вероятности:

Взяли не исходные фичи, а преобразовали их. Weight of Evidence или WoE — один из способов преобразования таргет-энкодинга. Он показывает предсказательную силу независимой переменной по отношению к зависимой переменной,то есть кодирует наши бины по отношению к таргету.
Поскольку WoE произошел из мира кредитного скоринга, его обычно описывают как меру разделения хороших и плохих клиентов. «Плохие клиенты» — те, кто не смог выплатить кредит, а «хорошие клиенты» — те, кто вернул деньги банку.
Считается этот показатель по такой формуле:

Формула расчёта WOE на примере задачи кредитного скоринга. Логарифм в формуле помогает убрать длинный хвост.
Суть в том, чтобы взять фичу и разбить её на бины / бакеты. Разбивать можно по-разному, например, в первом приближении мы равномерно разделили фичи на 10 бинов. В данном случае фича принимает значения от нуля до плюс бесконечности.
Далее мы считаем, сколько объектов Y=0 и Y=1 попало в бин. А потом рассчитываем доли нулей и единиц во всём нашем датасете. В сумме они дают 100%. Напомню, что Y=1 — класс, куда входят объявления, которые получают много ликвидности, Y=0 — противоположный класс.
Таблица с примером разбиения на бины:

Значение показателя WoE говорит нам, насколько в конкретном бине больше нулей (Y=0) или единиц (Y=1), чем в других.
Дальше если мы построим зависимость WoE от бина, то увидим, что некоторые бины очень близки друг к другу и их можно объединить в один бин, потому что у них примерно одинаковое влияние на таргетную метрику. Это видно на графике:

Зависимость WoE от номера бина.
Объединяем диапазоны, которые близки по степени влияния на таргет (WoE). Вот что это даёт:

Покажу, как выглядит объединение близких диапазонов на абстрактном примере:

Так выглядят таблицы после того, как мы объединили диапазоны, близкие по степени влияния на таргет.
Использовали метрику Information Value, чтобы оценивать ценность фичи. Information Value (IV) считается так:

Формула расчёта метрики Information Value.
Именно для максимизации этой метрики идёт разбиение на бины. Сумма всех значений в столбце IV показывает, насколько эта фича полезна. Принято следующее условное разделение IV:

Таблица со значениями метрики IV и данными о полезности фич.
Как мы реализовали AutoWoE в Авито Услугах
Одна из удобных библиотек, которая позволяет обучить бинарную классификацию с разбиением фичей на диапазоны по WoE — это библиотека AutoWoE от Сбера. Она требует минимум усилий по написанию кода и подходит для задач, где важна интерпретируемость факторов.
Библиотека AutoWoE от Сбера — это AutoML, в которую встроено всё необходимое. Вот что умеет эта модель:
- отбирает фичи по разным критериям;
- выбирает оптимальное разбиение каждой фичи;
- работает с дисбалансом классов из коробки;
- автоматически строит отчёты: метрики, скор-карту с разбиением фичей на диапазоны, влияние каждой фичи и диапазона;
- автоматически генерирует SQL-код для реализации модели в проде.
Полезные материалы:
Библиотека AutoWoE можно на GitHub. Там же найдёте тьюториалы с кодом обучения.
Основные этапы обучения AutoWoE:
1. Инициализируем объект класса. Тут много параметров, из важных можно выделить:
- ограничения на монотонность — monotonic;
- максимальное количество бинов, на которые можно разбить фичу — max_bin_count.
Вы либо задаёте монотонность фичи: допускаете, что фича влияет на таргет только положительно или только отрицательно. Либо говорите, что в зависимости от диапазона фича может влиять как в положительную, так и в отрицательную сторону.
Объясню на примере из задачи кредитного скоринга.
Если возраст клиента небольшой — до 22 лет — то, скорее всего, вероятность одобрения кредита будет низкой. С увеличением возраста вероятность одобрения будет повышаться, а когда дойдём до 50 лет, вероятность снова пойдёт к снижению. Это случай немонотонного влияния фичи на таргетный показатель — вероятность получить кредит.
А вот пример кода, где мы ожидаем, что фичи влияют на таргет монотонно: monotonic=True. И позволяем модели разбивать фичу максимум на 4 бина: max_bin_count=4:
from autowoe import ReportDeco, AutoWoEauto_woe = AutoWoE (interpreted_model=True,monotonic=True,max_bin_count=4,select_type=None,pearson_th=0.9,auc_th=.505,vif_th=10.,imp_th=0,th_const=32,force_single_split=True,th_nan=0.01,th_cat=0.005,auc_tol=1e-4,cat_alpha=100,cat_merge_to="to_woe_0",nan_merge_to="to_woe_0",imp_type="feature_imp",regularized_refit=False,p_val=0.05,verbose=2 )
2. Дальше фитим модель, предварительно собрав датасет с фичами и таргетом. А также считаем метрику качества бинарной классификации — ROC_AUC. Она показывает, насколько хорошего качества получилась модель.
auto_woe.fit(train[features+['target']], target_name='target')
pred = auto_woe.predict_proba(test[features+['target']])
print('roc_auc_score на test: ', roc_auc_score(test['target'], pred)
3. А затем формируем и анализируем отчёт. Я советую создать папку, куда он будет генерироваться, потому что там будет много разной информации. После выгрузки отчёт будет выглядеть так:

Выгруженный HTML-отчёт.
В нём будет общее саммари: описание датасета, например, доля таргета в train и test выборки, а также главный артефакт — скор-карта. Это таблица, состоящая из фичей, бинов и показателей WoE, COEF и POINTS. Выглядит она так:


Часть скор-карты из отчёта
В таблице мы видим фичи, например, median_reply_time. Она разбита на бины: median_reply_time <=15.75. И содержит значение метрики WoE -1.02 — это степень влияния на таргет.
Также у каждой фичи есть заданные параметры коэффициента (COEF) и баллы (POINTS).
COEF — это коэффициент, при каждой фиче. Он один для фичи, как и при любой логистической регрессии.
POINTS — это баллы, которые мы получаем, когда перемножаем значения метрики WoE и коэффициента. Их можно сравнивать между собой и понимать, какие значения приближают нас к таргету больше, какие меньше, а какие и вовсе тянут вниз.
Объясню, как интерпретировать эту скор-карту на примере.
В нашем отчёте можно заметить, что, если исполнитель будет отвечать на сообщения заказчиков в течение 15 минут (median_reply_time <= 15.75) — это приблизит его сделке на 0.65 балла.
А если пользователь будет отвечать на сообщение больше 118 минут (median_reply_time >= 118.25) — это ухудшит его шансы получить сделку на 0.33 балла.
Следовательно: чем быстрее исполнитель отвечает на сообщение, тем больше шансов, что заказчик решит купить его услугу. При этом у нас появляются пороги для рекомендации и в совете мы можем отправить человеку временные рамки: «Отвечайте в течение 15 минут и вы повысите шансы получить сделку».
После применения сигмоиды к полученным показателям можно узнать вероятность получения успешной сделки в каждом случае.
4. Дальше одной командой мы генерируем SQL-скрипт, который даёт все случаи разбиения (case when):
print (auto_woe.get_sql_inference_query('table_name'))
На выходе получаем готовый SQL-код для внедрения в продакшен уже без самой ML-модели. Показываю код с частью фичей:

Кусочек кода со всеми case when и разбиениями.
Мы один раз обучили модель, прогнали её в Python и потом можем применить её с помощью SQL-скрипта.
Как нашли немонотонную зависимость с помощью ML-модели
На первой итерации стоит задать параметр monotonic=False и посмотреть, будут ли интересные кейсы. Например, мы обнаружили, что, если цена в объявлении продавца сильно занижена — это влияет на ликвидность объявления так же плохо, как и завышенная цена.
Обычная линейная модель не нашла подобную зависимость — мы увидели это, только когда применили подход с WoE. Так это выглядит на нашей скор-карте:

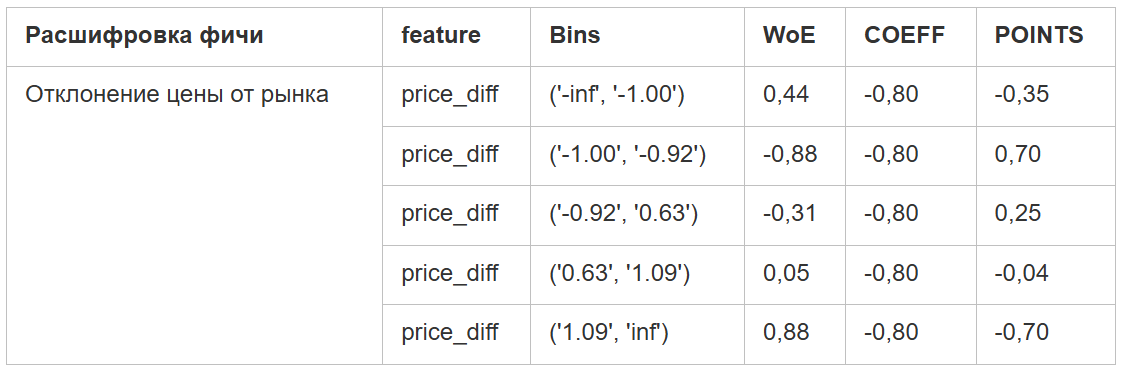
Таблица, на которой видна нелинейная зависимость ликвидности, количества сделок от цены
В чём преимущества работы со скор-картой
С помощью неё мы видим оптимальные разбиения: бакеты, пороги и наилучший бакет по каждой фиче. Например, рекомендуемое время ответа заказчику отличается для разных категорий услуг. Когда заказчику нужен эвакуатор для транспорта, оптимальное время ответа жёстко ограничено. А в других случаях исполнитель может отвечать в течение часа и это не будет снижать ликвидность.
В одной таблице можем сравнивать силу влияния бакета по параметру POINTS и понимать, что исполнителю стоит улучшать в первую очередь. Например, добавлять больше фотографий, менять цену или быстрее отвечать потенциальным клиентам.
Советы по работе с AutoWoE
Ставьте библиотеку AutoWoE в отдельном виртуальном окружении — venv. Рекомендуемая версия для Python 3.10 - 0.3.8b1:

Смотрите, откалиброваны ли вероятности, то есть выходы predict_proba модели. Если нет — то можно использовать разные методы, чтобы откалибровать выход модели и фактические вероятности единичек (Y=1) в датасете.
Стройте разные модели для отдельных сегментов, кластеров. Один глобальный минус AutoWoE — с помощью него не получится построить два абсолютно разных решения двух подклассов или сегментов, которые есть в вашей выборке.
То есть, если вы решите построить модели для двух принципиально разных типов данных с разными зависимостями и смешаете их в один датасет — ничего хорошего, скорее всего, не получится. Я рекомендую делать бизнесовое разбиение, например, на понятные вам сегменты или категории — на их основе строить отдельные модели и получать разные скор-карты.
Если не знаете, что у вас за выборка, и какие сегменты могут в ней содержаться, — постройте простую модель дерева решений (Decision Tree) и посмотрите, по каким фичам идёт разбиение ближе к корню дерева. Если ветки сильно отличаются (в одной ветке используется один набор фичей и разбиений, а в другой ветке иной набор) — возможно, это кандидаты, по которым можно строить разные модели AutoWoE.
Вся статья в пяти пунктах
Решили внедрить модель для повышения ликвидности объявлений. На Авито есть исполнители услуг, у которых немного сделок. Чтобы они получили возможность увеличивать число продаж, мы внедрили систему рекомендаций, которые помогут сделать объявления более привлекательными и повысить вероятность сделки. Подсказки формируются с помощью интерпретируемой ML-модели.
Модель анализирует опыт успешных продавцов и даёт на основе этого рекомендации тем, у кого мало или вовсе нет заказов. Мы анализируем, как использование разных инструментов влияет на целевой таргет — количество звонков или сообщений в чат. Под инструментами имеем в виду, например, время ответа на сообщение от потенциального заказчика, количество фотографий в объявлении, соответствие цены услуги рыночным показателям, использование платных инструментов продвижения.
Для реализации идеи мы использовали библиотеку AutoWoE от Сбера. С помощью WoE можно разбивать фичи на бины и вычислять вероятность влияния каждого бина на таргет. Библиотека отбирает фичи по разным критериям, выбирает оптимальное разбиение каждой фичи на бины, автоматически строит отчёты и генерирует SQL-код для реализации в продакшене.
На выходе модель формирует скор-карту инструментов, где оценивает степень их влияния на таргет. Эти скор-карты дальше можно использовать для ваших целей. Например, мы оцениваем влияние разных инструментов на ликвидность объявлений, а потом переводим эти показатели в рекомендации для пользователей нашей площадки. К примеру, предлагаем отвечать на сообщения в течение определённого времени или советуем добавить в объявление больше фотографий.
После проведения А/Б-теста мы убедились, что модель помогает растить метрики целевых контактов — звонков и сообщений в чат. Выполняя рекомендации, исполнители получают больше сделок.
Спасибо вам за уделенное статье время!
Узнать больше о том, как инженерам живется в Авито, вы можете здесь, в нашем хабраблоге, на сайте AvitoTech и в телеграм-канале.
