




Привет! Я Владимир Морозов, senior DS engineer в команде модерации Авито: в основном занимаюсь автомодерацией видео, но развиваю и другие проекты. Это я:

В статье рассказываю, с какими трудностями мы столкнулись при модерации видео в условиях небольшого количества данных, и как их решили. Думаю, материал будет полезен всем, кто занимается похожими задачами в крупных продуктовых компаниях.

Зачем Авито следить за видео и какие вообще есть подходы к модерации
Модерация в Авито — это выявление проблем в объявлениях, которые люди публикуют на площадке. Размещения проверяют на соответствие правилам сервиса и могут отклонить их, если что-то не так.
Сейчас в объявления можно добавлять видео — это помогает покупателям быстрее выбирать товары, а продавцам — подтолкнуть заинтересованных людей к сделке. Но видео тоже нужно модерировать, ведь там могут быть нарушения.
Подходы к модерации бывают разные, и их выбор зависит от задачи. Например:
Премодерация или постмодерация. Если риски нарушений большие, а модерация проходит быстро — лучше проверять объявления перед публикацией. А если рисков мало, то можно делать использовать постмодерацию.
Ручная или автоматическая модерация. Ручную модерацию проще запустить: достаточно привлечь людей, чтобы они начали искать нарушения. Но тут есть сложности: например, нужно следить, чтобы они работали добросовестно.
У автоматической модерации тоже есть свои минусы — о них подробнее расскажу ниже — и её сложнее запустить. Но в сравнении с ручным подходом у неё много преимуществ, которые помогают быстро масштабироваться: такая модерация дешевле, быстрее и даёт более предсказуемый результат.
Какой была наша первая система модерации видео и с какими проблемами мы столкнулись
Видео — новый домен, с которым в Авито раньше не работали. К тому же быстро построить автоматическую модерацию проблематично. Поэтому на первом этапе мы сделали такую систему:
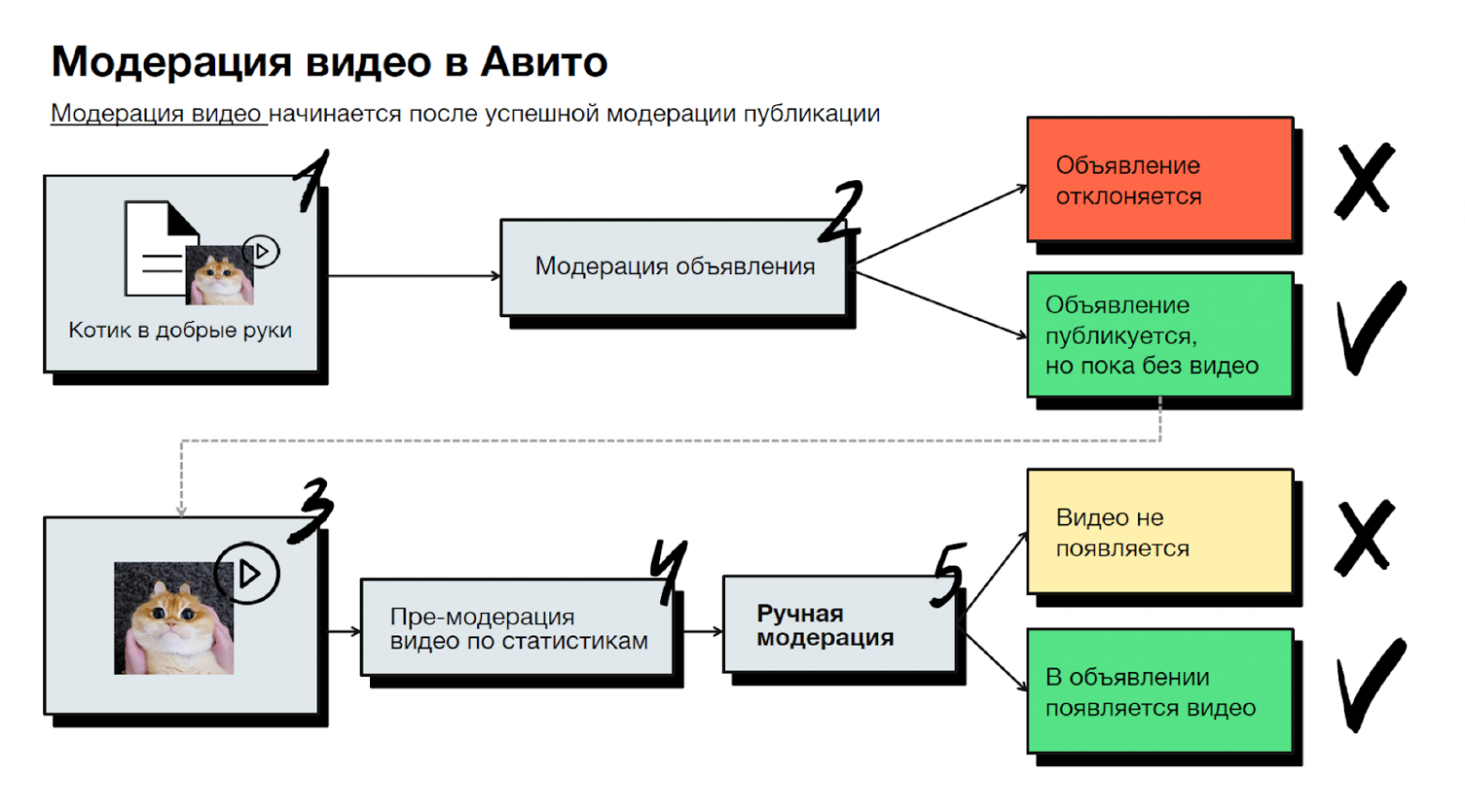
Суть подхода: если в самом объявлении нет нарушений, мы публикуем его, но сначала без видео. Затем ролик проходит премодерацию и ручную модерацию. Если всё в порядке — он появляется в объявлении. Мы сделали так для того, чтобы не увеличивать время модерации из-за возможности добавить видео.
Теперь поговорим о нарушениях, которые мы ищем во время модерации. В задаче можно выделить две составляющие:
- причина нарушения — например, люди на видео просят людей переходить на другой сайт;
- домен нарушения — в кадрах видео, его качестве, в аудио или в связи публикации и ролика. Например, если в объявлении о продаже квартиры добавляют видео с котиками.
Так как все видео раньше проходили только через ручную модерацию, то проявились все недостатки такой системы. А именно:
- Затраты на ручную модерацию. Чем сложнее объект, тем дороже модерация, и видео требует больше затрат, чем изображения.
- Сложно управлять потоком модерации. Если количество контента вырастет, придётся нанимать новых сотрудников. А если его станет меньше, освободившихся людей нужно будет чем-то занять.
- Человеческий фактор. Ручную модерацию нужно очень качественно проверять, но это не всегда получается — иногда бывают конфликты.
- Время проверки. Ручная модерация в разы медленней автоматической.
Поэтому мы решили начать постепенный переход на автоматическую модерацию.
Как мы собрали данные для автоматической модерации
Когда к нам в отдел пришли за созданием автоматической модерации видео, мы думали, что у нас будет много данных хорошего качества и с явной разметкой, — так что мы сможем легко обучить модели. Реальность оказалась сложнее и вот почему:
- Данных было мало. На тот момент возможность добавить видео внедрили совсем недавно, ей мало пользовались, нарушений в большинстве роликов не было. Поэтому поиск данных для обучения моделей оказался непростой задачей.
- Разметка была шумной, потому что в первую очередь предназначалась для оценки работы ручной модерации. Например, не было разметки на домены или подробной разметки на причины нарушений.
- По правилам хранения, видео с нарушениями удалялись спустя несколько дней после замены на исправленные версии, поэтому важные данные не накапливались в значительном объеме.
Поэтому для большого количества задач нам пришлось использовать открытые датасеты, парсить YouTube и разные видео-стоки.
Встречались забавные датасеты — например, датасет на насилие, где пара людей в комнате разыгрывали разные сцены. Но по реакции было непонятно, насилие это или нет: один изображал, что бьёт второго палкой, а при этом оба смеялись.
Какие технологии используются в модерации сейчас — разбираю по доменам данных
В итоге мы собрали видео и разбили их на домены, о которых я писал выше: видеоряд, аудио, метаданные и информация из объявления. Расскажу про каждый.
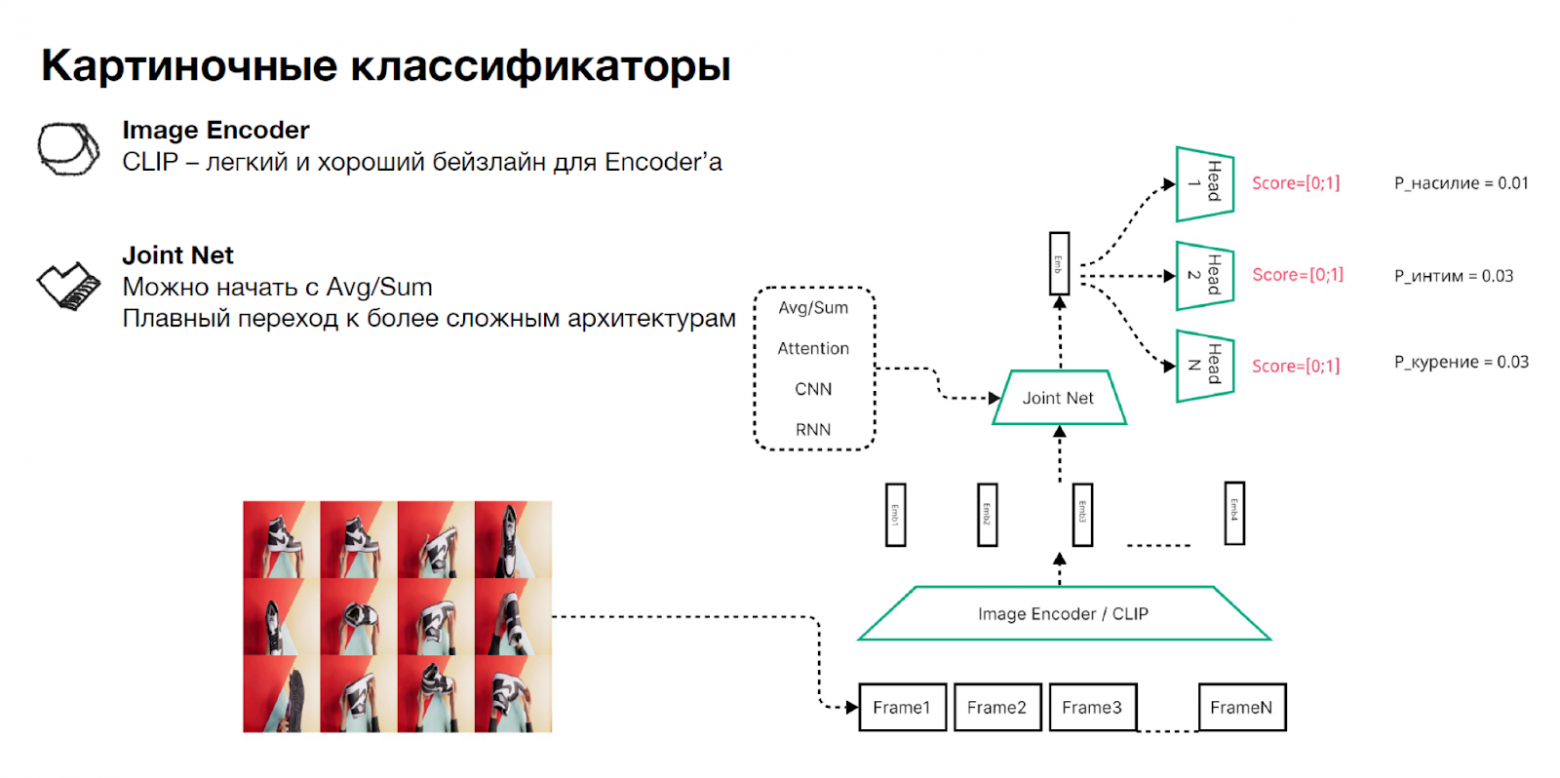
Модерация видеоряда. Вот как работает наша модель:
- Выбираем фреймы из видео. Эту задачу можно решать по-разному: например, брать случайно, брать каждый N-й, ключевые фреймы или проводить кластеризацию. Главное учитывать, что некоторые методы можно легко взломать (привет, 25 кадр).
- Преобразуем фреймы для классификации. В качестве энкодера можно использовать CNN/CLIP/BLIP. Третий по нашим бенчмаркам показывает лучшее качество, но можно начать и с CLIP, что мы и сделали.
- Агрегируем фреймы в один эмбеддинг с помощью Joint Net. В качестве бейзлайна всегда можно взять усреднение или максимум, а потом постепенно перейти к нейронкам. Для коротких видео это весьма качественный бейзлайн, который даёт хорошие метрики.
- Обучаем классификационные головы под каждую из причин. Получается, что у нас много голов под разные задачи, их легко добавлять и трекать качество, а самая тяжёлая часть — получение эмбеддинга видео — считается всего один раз. Всё прекрасно.
Тут мы не используем никакие дополнительные фичи, например аудио, потому что на старте проекта это значительно усложняет разработку. Схема работы модерации видеоряда:
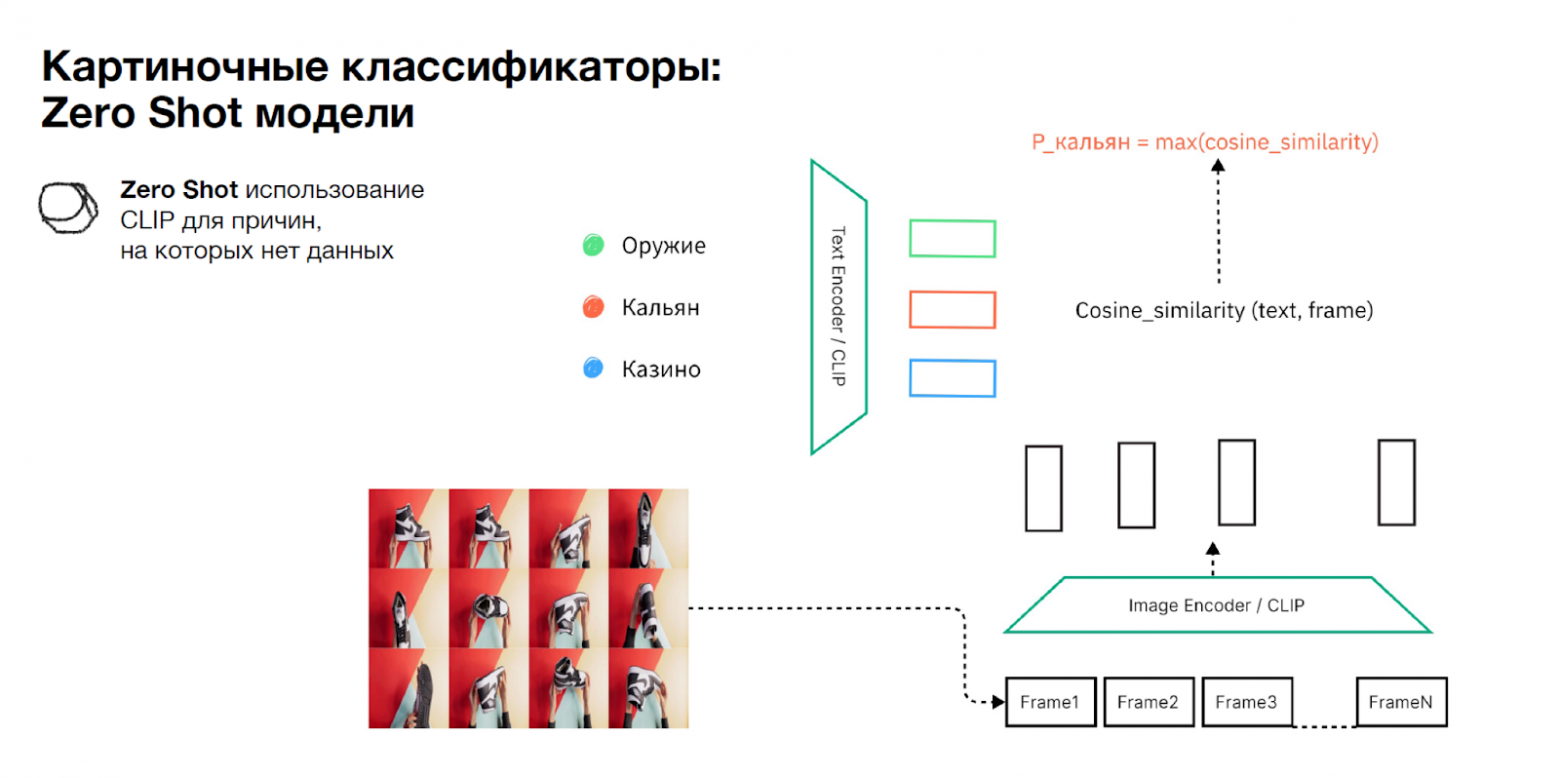
Но иногда бывает, что данных нет вообще — как и времени их собирать. Например, хочется быстро покрыть какую-то не очень важную причину. Скажем, отклонять видео, если на них появляется кальян.
Тогда можно использовать, например, Zero Shot-подход для CLIP, так как он обучался на сопоставление текста и изображений. Мы кодируем промпты для поиска и фреймы, а затем вероятность класса вычисляется как максимальный скор между промптом и перебором всех фреймов. Zero Shot модели в модерации видеоряда:
Но на самом деле, связь между фреймами не всегда важна, в основном это action recognition или какие-то сложные уловки нарушителей. Так что если у вас в компании есть картиночные классификаторы для нахождения нарушений, то можно попробовать и их.
Также большой пласт нарушений кроется в логотипах — например, недобросовестные пользователи могут уводить на видео людей к конкурентам. Такие проблемы мы тоже научились находить, используя детектор и потом векторный поиск по базе логотипов. Как мы ищем логотипы в видео:
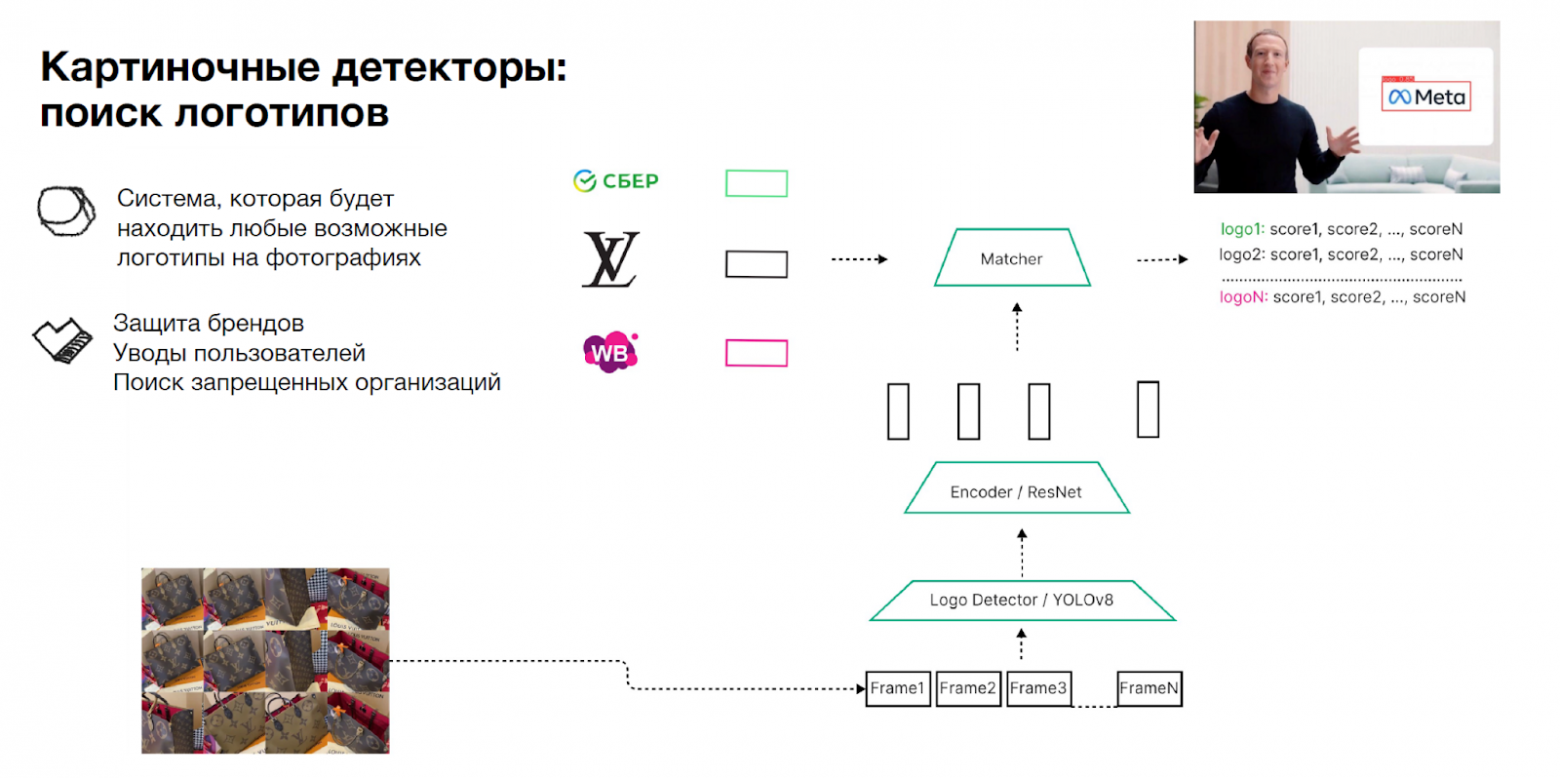
С выявлением лиц немного сложнее — их тоже важно находить, потому что недобросовестные пользователи могут, например, нарушать авторские права и брать чужие фото. Тут мы прогоняем кадры через какой-то легковесный классификатор, который точно говорит, есть ли на фрейме изображение. Оставляем только фреймы, где точно есть нарушение, и сравниваем картинки с лицами, которые есть у нас в базе. Как мы ищем лица на видео:
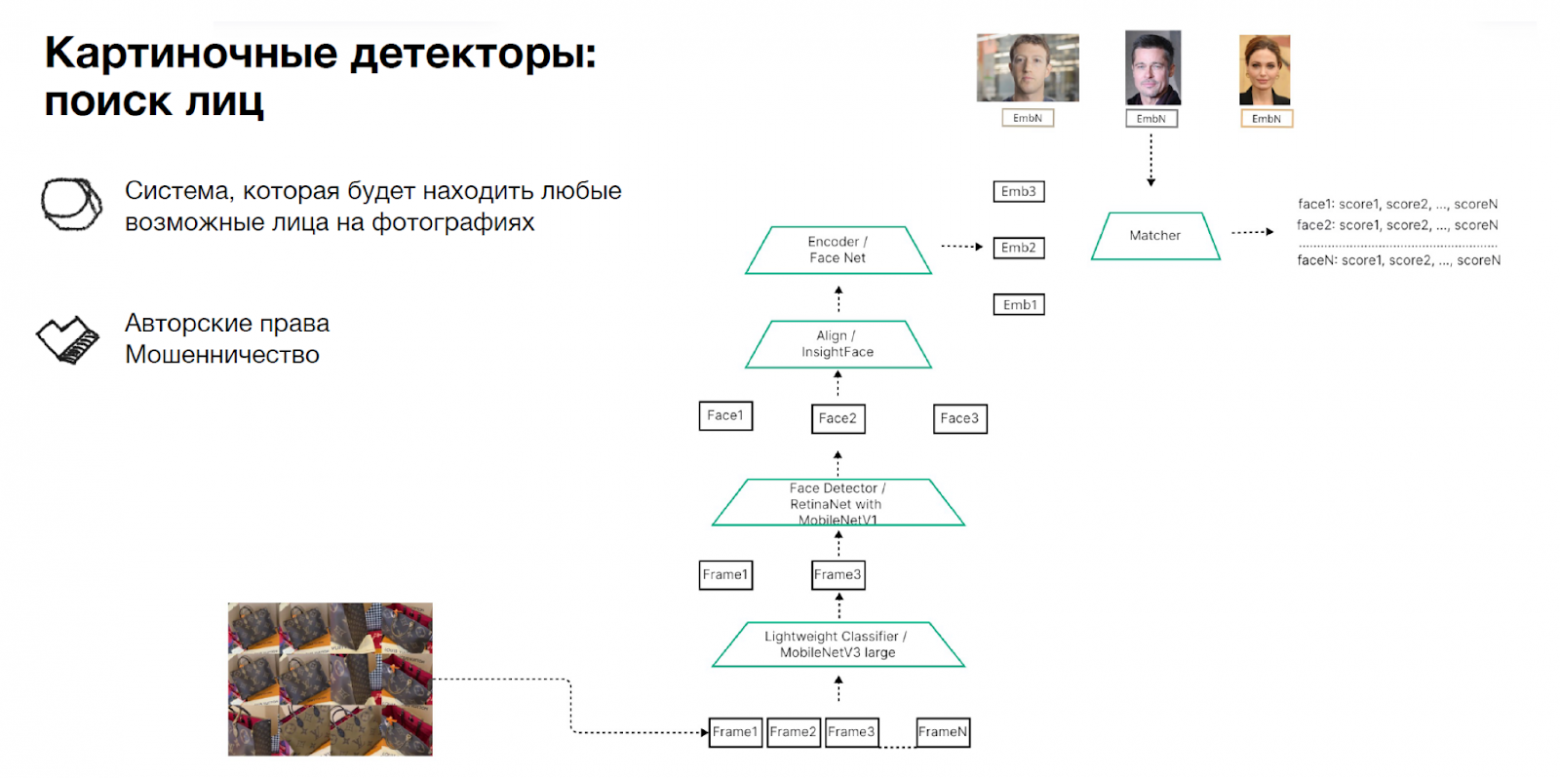
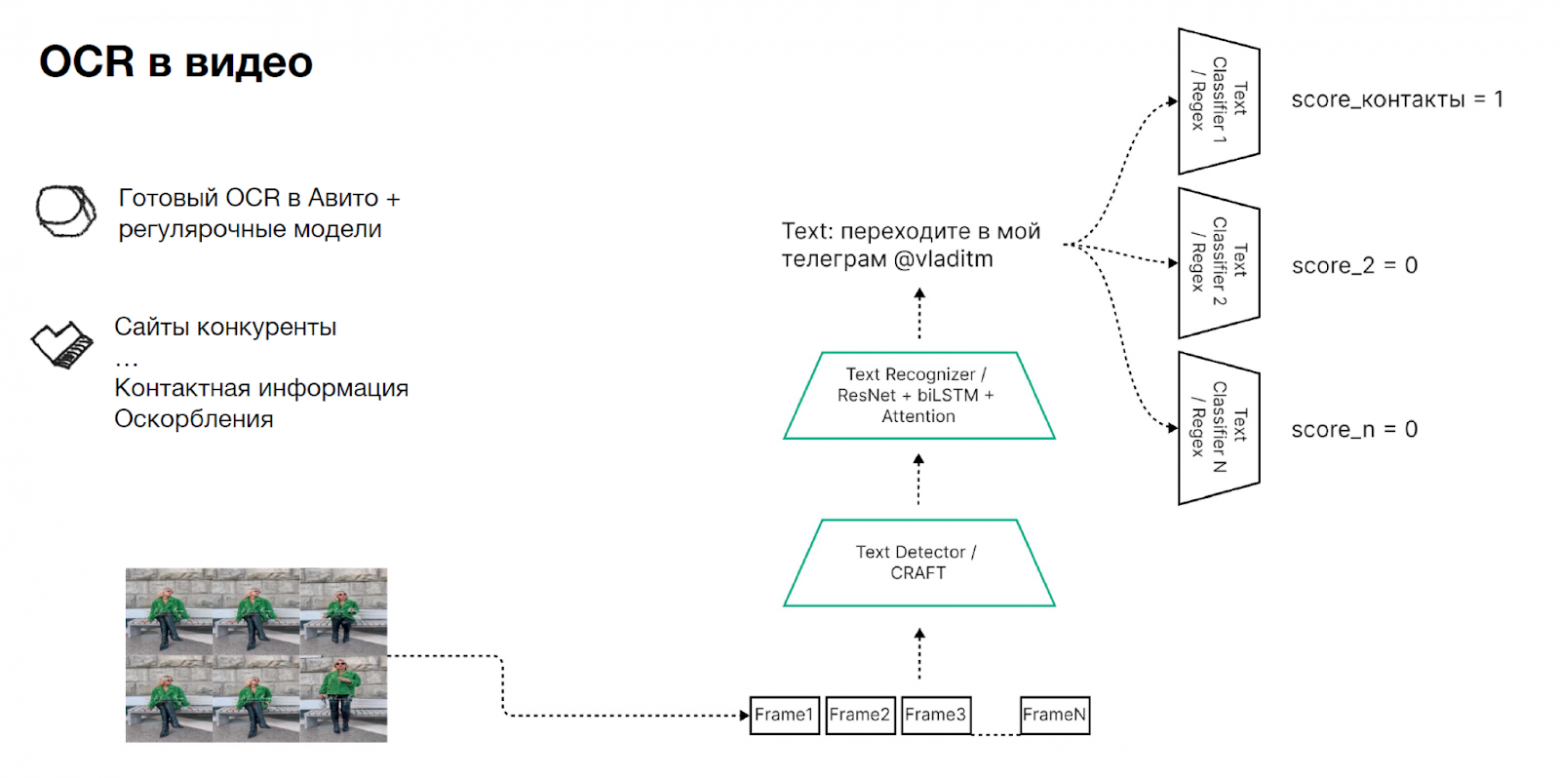
Модерация текстов в видео. Большой пласт нарушений кроется в текстах на видео — например, там могут быть оскорбления или попытка увести на сайты конкурентов.
Здесь на помощь приходит OCR, который может дать нам весь текст из видео, а дальше нужно найти в этом тексте нарушения. В качестве бейзлайна, — особенно когда у вас нет данных, но вы знаете, что хотите находить, — можно использовать регулярочные модели. Как мы находим среди фреймов текст с потенциальными нарушениями:
Модерация аудио. Здесь работа похожа на ту, что происходит с OCR, только мы используем транскрибатор для аудио. В качестве бейзлайна мы взяли Whisper — он мультиязычный и весьма хорошо работает, — и дообучили на данных Авито. Далее схема такая: аудио поступает на вход, мы транскрибируем его через Whisper и прогоняем через всевозможные текстовые классификаторы для поиска нарушений. Схема модерации аудио:
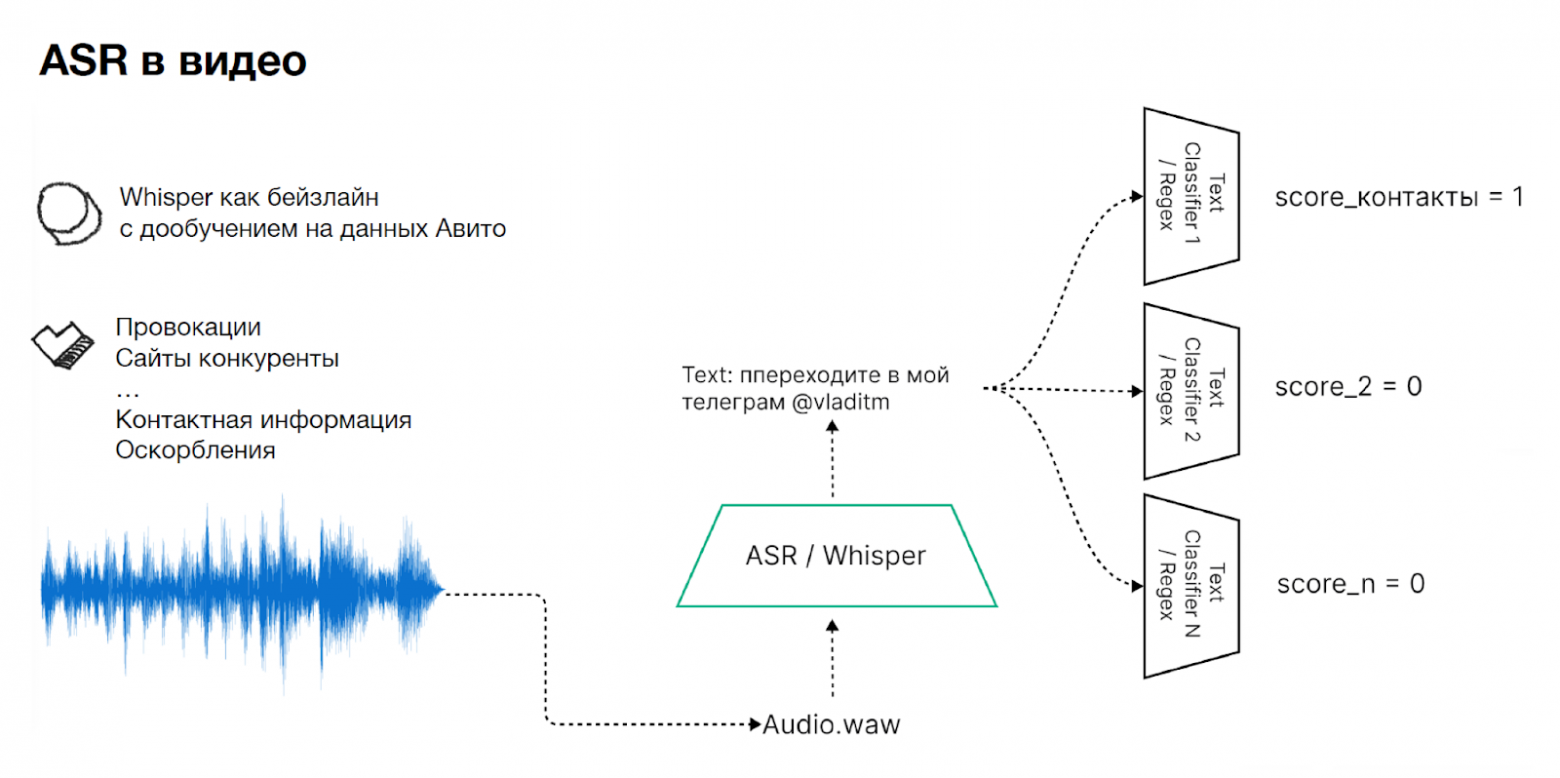
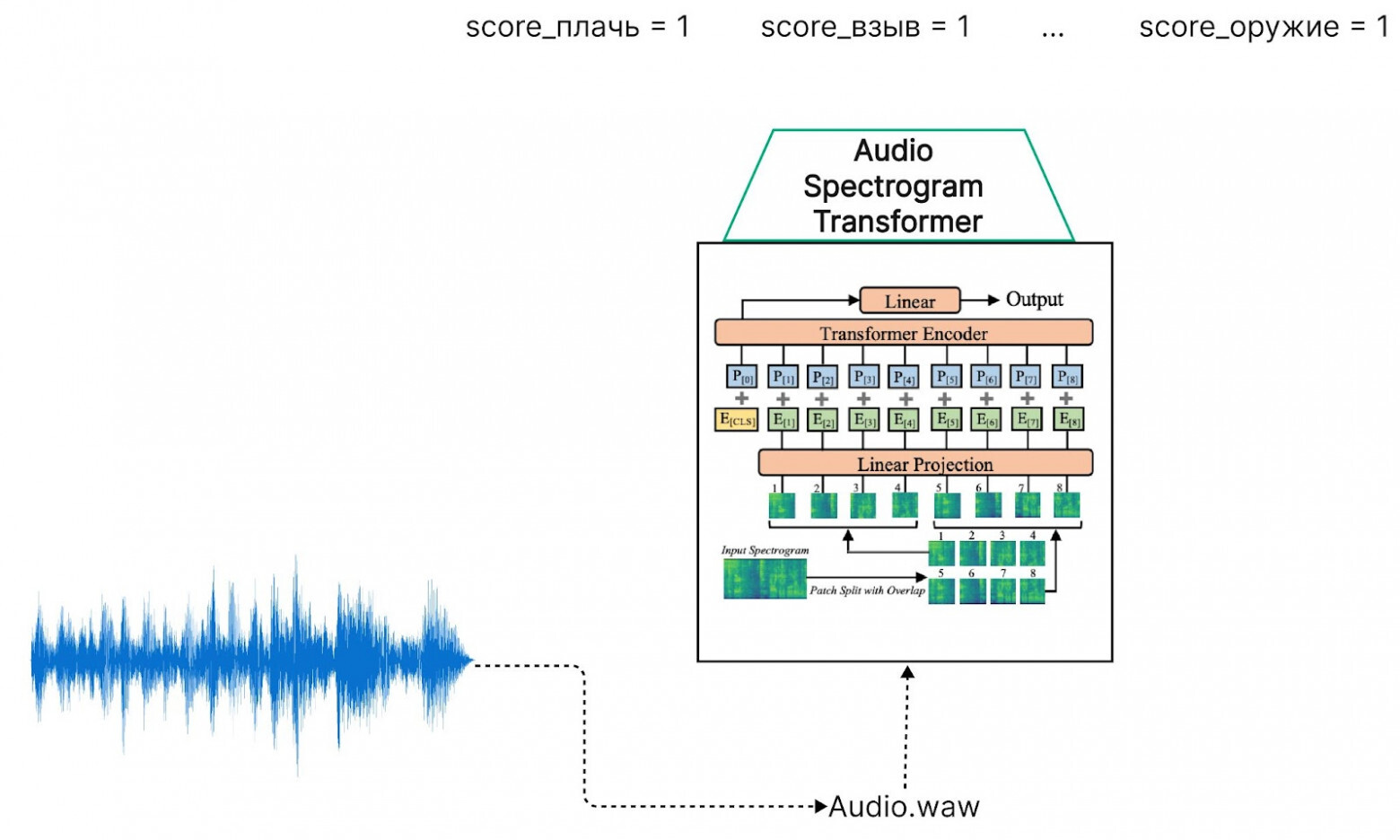
Ещё часть нарушений в аудио можно найти не в речи, а по звукам — например, громкие посторонние шумы. Для покрытия таких кейсов мы используем аудио-классификатор Audio Spectrogram Transformer, который прекрасно находит разные нарушения в звуках. Аудио-классификатор Audio Spectrogram Transformer:
Модерация качества видео. Чтобы исключить ролики совсем плохого качества, можно проанализировать метаданные видео: смотреть на битрейт или FPS (frames per second). Битрейт показывает, сколько битов меняется при изменении нового фрейма, а FPS — сколько фреймов меняется за секунду. На метаданных можно обучить какой-то базовый классификатор, чтобы он предсказывал качество видео.
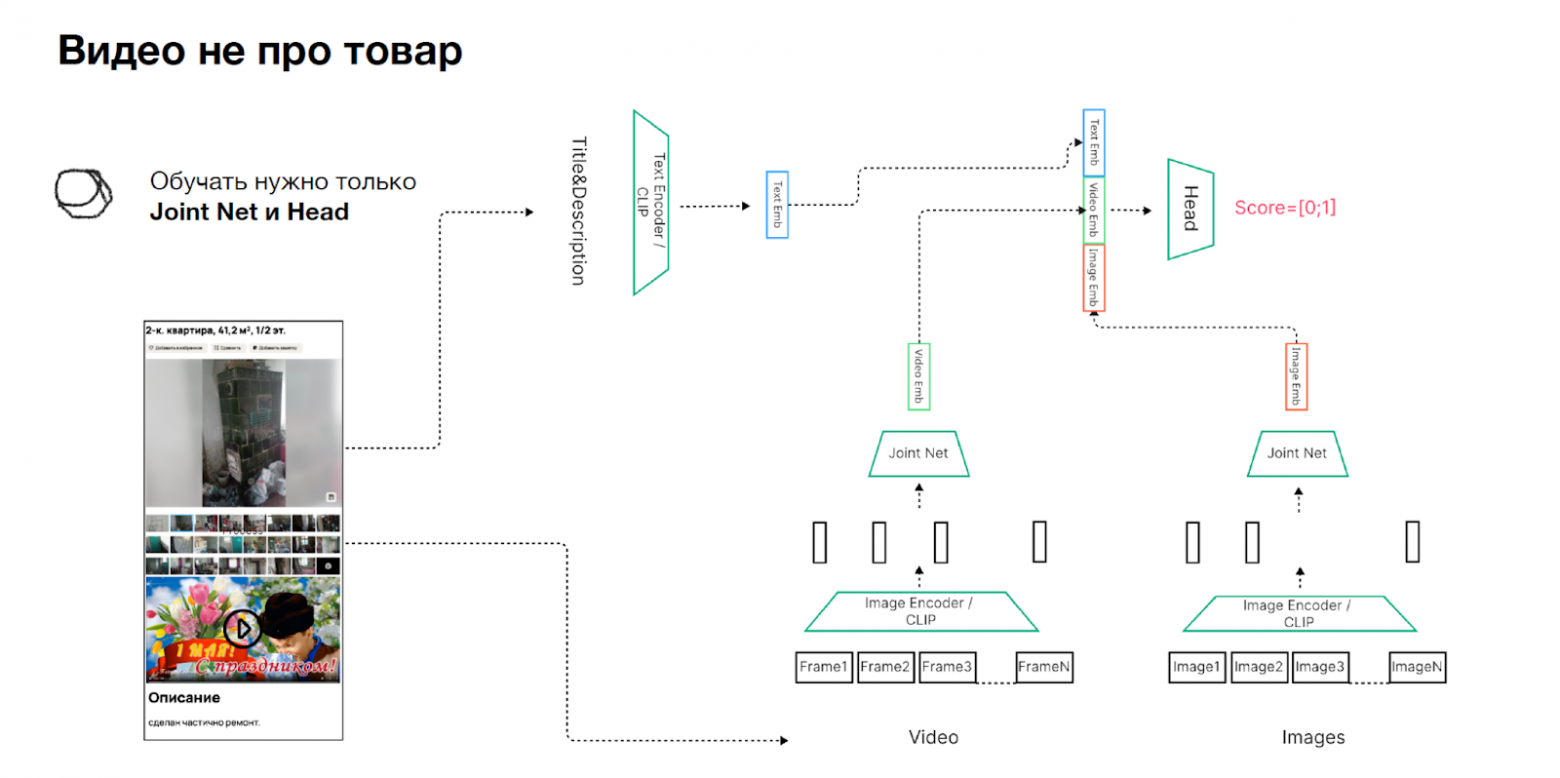
Проверка: подходит ли видео для объявления. Здесь мы тоже решили не изобретать велосипед и переиспользуем CLIP: получаем эмбеддинги для всех фреймов, то же самое делаем для картинок и текста в объявлении. Потом все эти эмбеддинги аггрегируем и прогоняем через классификационную голову, которая подсказывает, есть нарушение данного типа или нет:
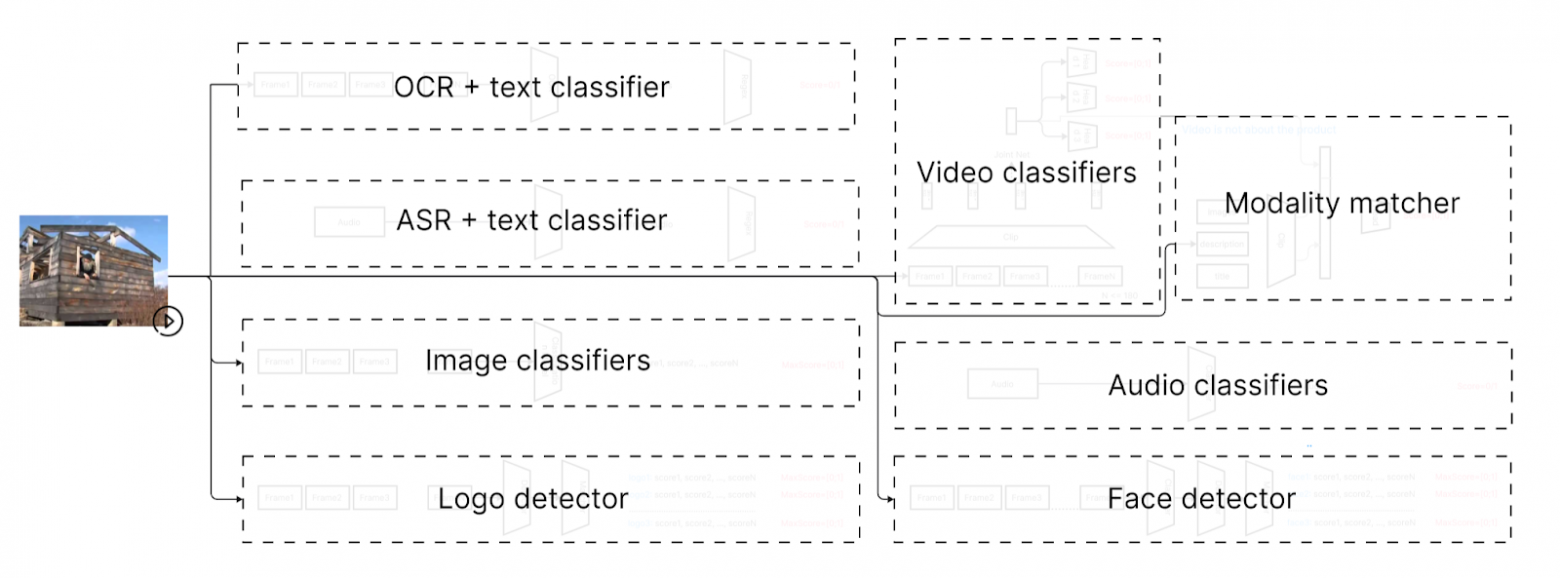
Что в итоге: общая схема автомодерации. Это не одна большая модель, а скорее множество моделей разной сложности — они взаимодействуют и вместе говорят, есть нарушение в видео или нет:
Сейчас большинство роликов проходят автомодерацию и публикуются на сайте гораздо быстрее, чем раньше, когда всё работало в ручном режиме. Сейчас ручную проверку проходят только те видео, где автоматическая модерация обнаружила нарушения, а это небольшой процент роликов.
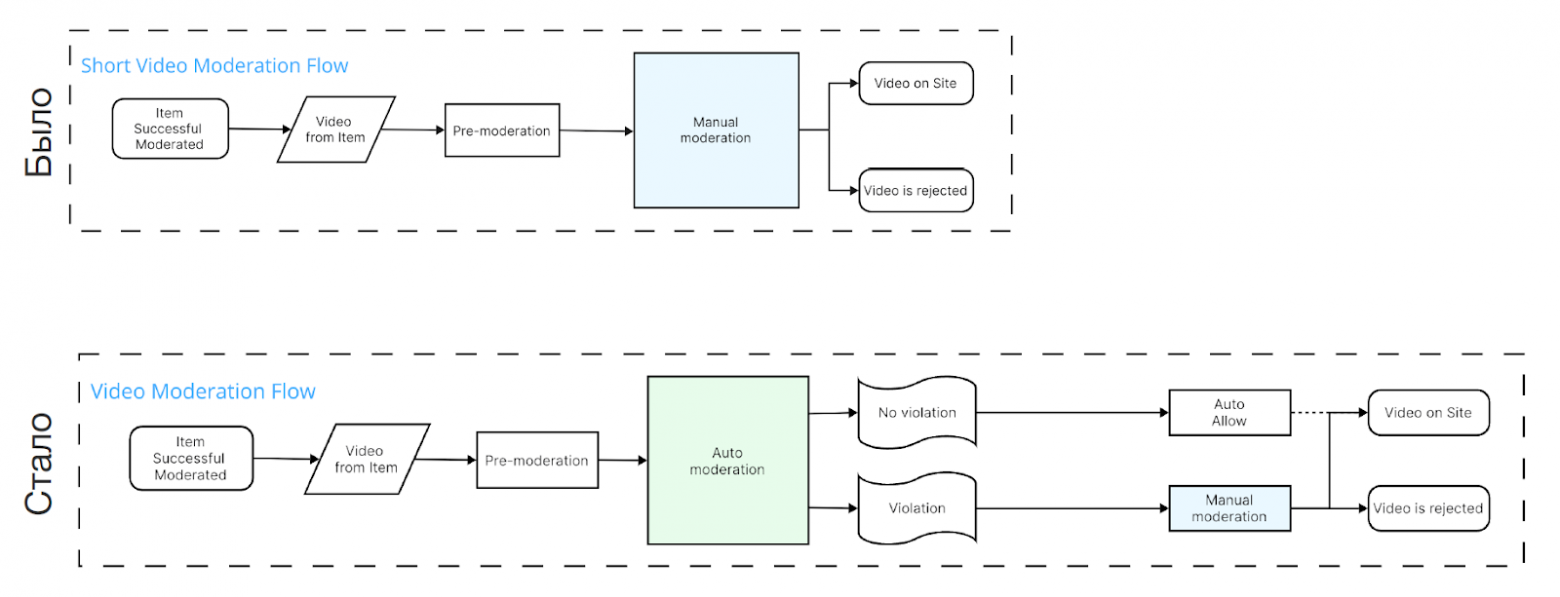
Первая система vs актуальная система модерации видео:
Как мы анализируем работу модели автомодерации
Обычно смотрят на два типа метрик:
- Бизнес-метрики. Например, уровень автоматизации или доля ошибок.
- ML-метрики: Recall, Precision в целом и в разных разрезах — по доменам, по моделькам.
Как мы анализируем эффективность модерации:
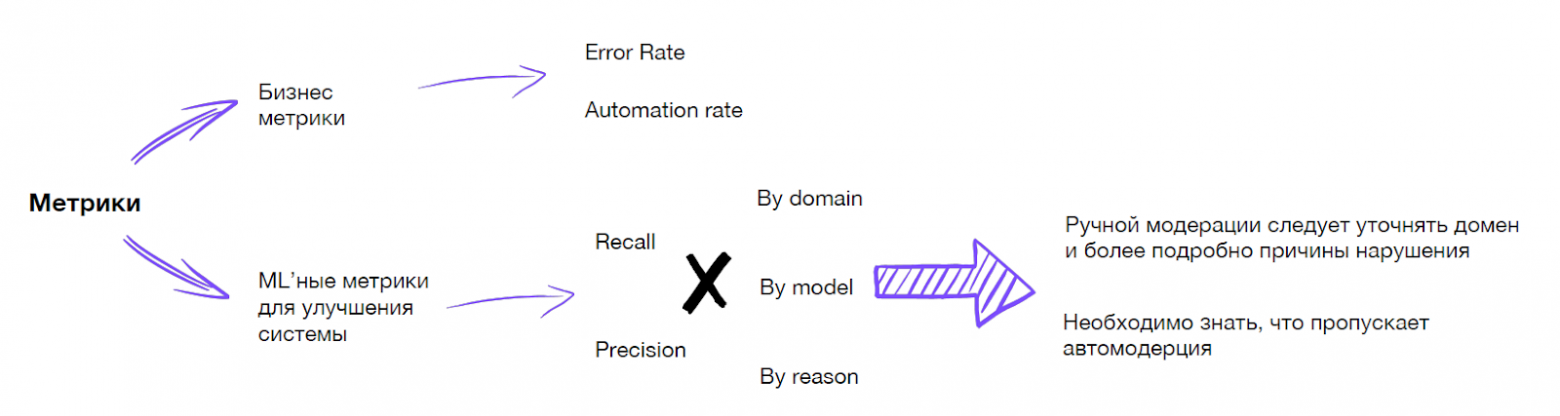
Чтобы оценить ML-метрики, мы ввели два основных изменения: поменяли инструкцию по разметке видео и добавили небольшой сэмплер, который кидает часть видео, где мы не нашли нарушения, на ручную модерацию.
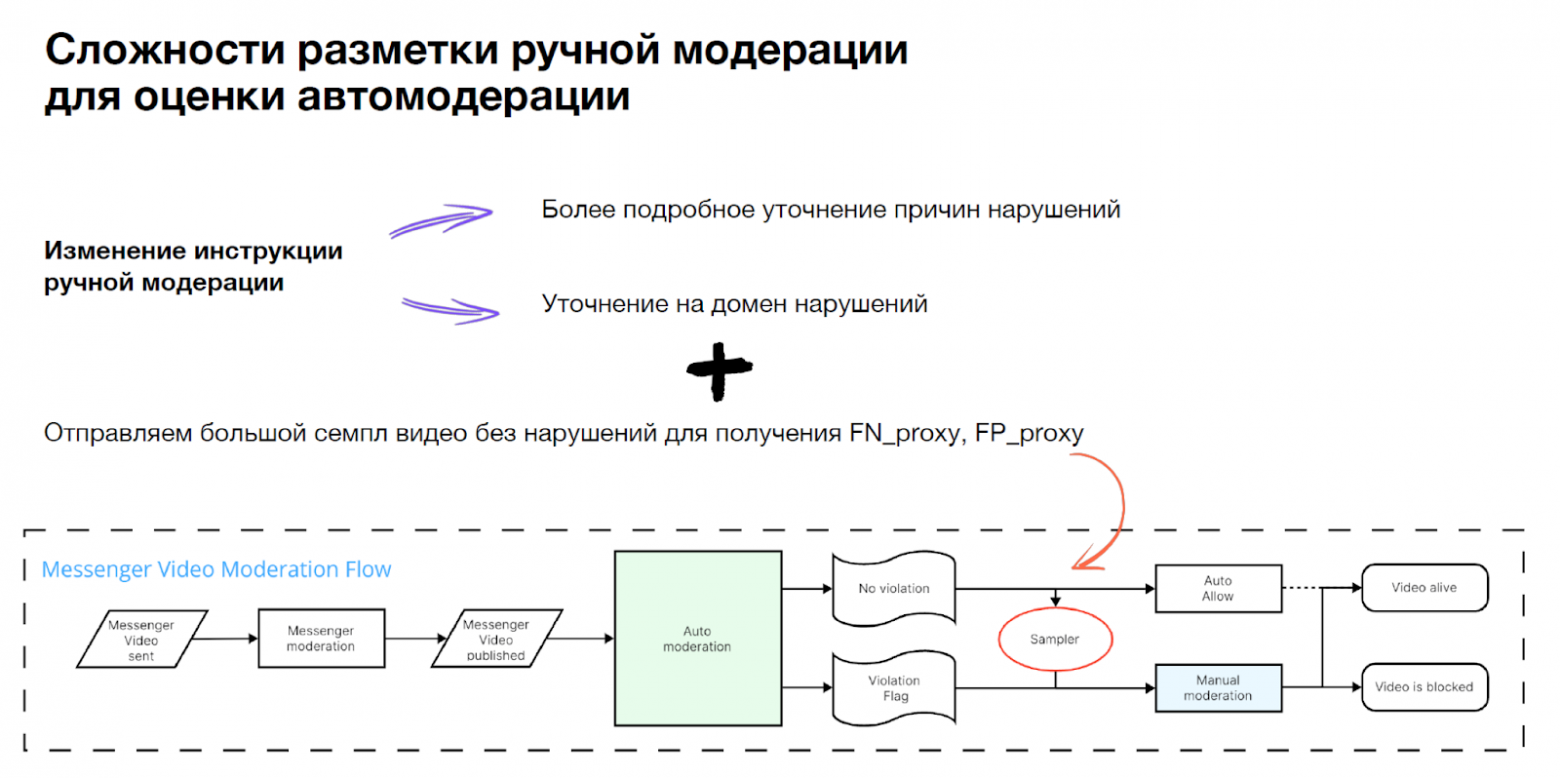
Если автомодерация нашла нарушение, мы можем найти True positive и False positive. Если автомодерация ничего не нашла, основная часть видео публикуется на сайт, и какой-то сэмпл отправляется на ручную модерацию, из которого мы достаем False negative и True Negative для оценки ML-метрик.
Вместо выводов
В итоге благодаря грамотной декомпозиции задач и использованию уже существующих решений нам удалось покрыть все ключевые причины нарушений в видео без необходимости «изобретать велосипед». Это помогло оптимизировать процессы модерации видео — повысить их эффективность и снизить затраты.
Помимо модерации сложных доменов вроде видео, у нас в команде есть и другие амбициозные проекты. Например, автоматическое исправление нарушений за пользователя, применение методов few-shot для текстов и изображений, блокировка дублей и всё это — в высоконагруженной системе с большим влиянием на всю компанию.
Спасибо за уделенное статье время! По любым вопросам о нашем опыте в модерации видео можете писать мне, контакты для связи:
- Telegram: @vladitm
- LinkedIn: Vladimir Morozov
А если вам интересны подобные задачи, приглашаем вас присоединиться к нашей команде — скучно точно не будет! О том как это сделать — по ссылке.
