




Всем привет! Я Юлия Трусова, QA-инженер в Авито. Хочу рассказать вам про свой опыт проектирования и внедрения процесса работы с обращениями пользователей — SPT. Некоторые коллеги пытались расшифровать эту аббревиатуру как Support problem ticket, но это не аббревиатура вовсе. Это сокращённое название проекта SUPPORT в Jira, сгенерированное автоматически, где мы храним тикеты.

Нам было важно настроить процесс работы с пользователями так, чтобы мы могли оперативно реагировать на проблемы, предоставлять варианты решений и быстро исправлять ошибки. Ещё нам хотелось знать мнение юзеров о реализованных фичах и фича-реквестах.
Статью будет полезно почитать тем, кто проектирует подобные процессы или поддерживает их.
Как работает клиентский сервис в Авито
В Центре клиентского сервиса работает больше 1200 агентов поддержки и модерации. Эти отделы работают 24/7, чтобы помогать клиентам в любой момент. Но в процессе обработки обращения участвует не только специалист поддержки — часто для решения вопроса пользователя нужна помощь технических команд.
В итоге получается такая цепочка обработки обращения:
- Пользователь обращается в поддержку.
- В HelpDesk автоматически формируется тикет-инцидент.
- Если пользователь сообщает о баге, агент заводит тикет-проблему и связывает его с тикетом-инцидентом. Тикет-проблема нужен для агрегации одинаковых инцидентов.
- На основе тикета-проблемы координаторы заводят задачу в Jira в проекте SPT и назначают её на нужный юнит.
Схематически это выглядит так ↓
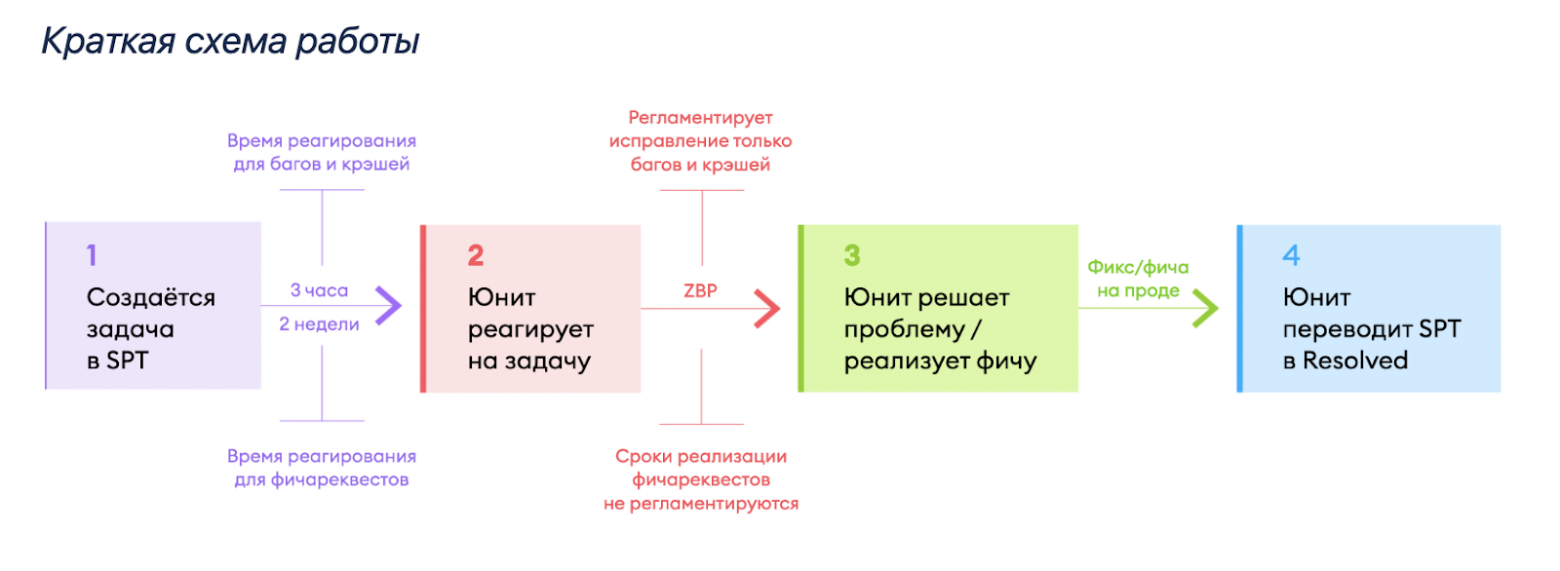
Первоначально процесс был настроен только на баги, но сейчас он расширен до работы с крэшами и фичареквестами
Командам нужно максимально быстро отреагировать на прилетевший тикет: понять, к ним ли он относится, проставить приоритет, предоставить временное решение, если оно есть. Это поможет координатору оперативно донести до юзера обходной путь, чтобы он смог продолжить пользоваться сервисом. Для исправления багов мы придерживаемся Zero Bug Policy: используем шкалу P0-P4, где P0 — самый серьёзный баг. Подробнее про концепт ZBP можно почитать в моей прошлой статье.
Дальше расскажу про значимые моменты, на которые стоит обратить внимание при реализации процесса, который регулирует получение и обработку обращений от пользователей.
Понимание зон ответственности
Чем больше команд, тем сложнее помнить, кто и за что отвечает. Поэтому нужен единый источник информации об этом, который будет полезен саппорту и коллегам внутри для оперативной связи по любым вопросам.
У нас для этого была сводная табличка в Confluence: там были описаны зоны ответственности и каналы в корпоративном мессенджере. Команды вели эту таблицу самостоятельно. Поначалу приходилось всех тыкать палочкой и просить закинуть данные, но сейчас большинство команд молодцы и оперативно обновляют информацию без напоминаний.
Единый проект в таск-трекере
Общее пространство для всех тикетов упрощает жизнь не только оунерам процесса, но и командам. Таким проектом легко управлять, кастомизировать под ваши нужны и собирать метрики.
А еще можно настроить интеграцию с другими системами, чтобы сразу донасыщать тикеты техническими деталями. Это поможет командам тратить меньше времени на обработку проблем.
Мы делили задачи на три типа: Bug, Crash, Feature. Они хранились в проекте SPT в JIRA. У нас была настроена интеграция с HelpDesk — это система, в которой работает саппорт. Она позволила нам:
- Выводить счетчик количества обращений от пользователей, который обновляется при поступлении новых запросов.
- Проваливаться в сырые обращения, если не хватило каких-то данных.
- Выводить информацию об обращениях ключевых клиентов и дополнительной нагрузке на саппорт.
Всё это позволяло командам объективнее приоритизировать проблемы и брать их в работу.
Из минусов — нельзя было переносить или клонировать задачи в свои проекты, потому что так слетали все кастомные поля.
Умная среда
Если вы хотите, чтобы команды придерживались процесса — упростите им жизнь и уменьшите шанс где-то ошибиться или что-то забыть.
- Таск-трекер
Хороший таск-трекер позволяет настроить проект под потребности. Вы можете сразу выставлять приоритет, добавлять тикет в спринты, настраивать флоу так, чтобы невозможно было перевести статус без заполнения дополнительных полей.
Например, чтобы ребятам в дальнейшем было проще анализировать причины возникновения проблем, мы сделали обязательным заполнение поля bug reason при изменении статуса задачи; автоматическое проставление Due Date при выставлении приоритета и установили пороги на количество обращений, при котором нельзя выбрать низкий приоритет.
- Нотификации
Это просто спасение, когда большую часть времени мы проводим в рабочих мессенджерах и почти не заглядываем на почту. Они не дают забыть про рутинные вещи и напоминают о выполнении определённых действий.
Нотификации могут быть:
- процессные — их получают все команды (например, если появляется новый тикет),
- кастомизированные — их можно настроить под себя,
- в виде сводок — ежемесячные апдейты для тимлидов и менеджеров.
Их можно настроить так, чтобы они падали в конкретный канал команды и давали подсказки о следующих действиях.
Например, когда мы добавили дополнительную нотификашку о скором нарушении времени реагирования (за 15 мин.), количество нарушений снизилось до минимума.
Совет. Чтобы нотификашки не пропускали и охотнее обрабатывали, добавьте к ссылке на задачу краткую инструкцию, что именно делать, или ссылку на документ с информацией по процессу.
Документация
Актуальная документация облегчает жизнь командам и тем, кто поддерживает процесс. На её написание придется потратить время, но это быстро окупится — вместо ответов на вопросы коллег можно будет кидать им ссылки из статьи.
Мы храним документацию в Confluence. Она состоит:
- из описания полного процесса — для тех, кто хочет знать все детали,
- из краткой схемы — чтобы освежить основные моменты,
- из инструкции для саппорта,
- из FAQ по основным кейсам и техническим особенностям,
- из лайфхаков и полезных советов.
Предупреждать саппорт об изменениях
На базовом уровне — предупреждать коллег по факту выкатки, на продвинутом — сильно заранее, чтобы они успели подготовить внутренние новости и рассказать про них агентам поддержки. Если заранее предупредить саппорт, они смогут предоставить актуальную информацию пользователю по изменениям. Это снижает количество «ложных» тикетов, которые багами не являются.
Например, у нас есть отдельный регламент о предупреждении саппорта об изменениях, новых фичах или А/B-тестах.
Поддержка сверху
Если руководство следит за метриками процесса и задает неудобные вопросы командам, которые сильно нарушают процесс, то он работает намного бодрее.
Например, мы делали регулярные сводки, добавляли метрики процесса к общим техническим и бюджетным метрикам юнитов или кластеров и привязывали их к Team Maturity Model.
Рефлексия
Можно бесконечно фиксить баги и тушить пожары, но лучше предпринять меры, чтобы их предотвратить.
Для крупных проблем мы старались своевременно проводить разборы по типу LSR, а для остальных регулярно смотрели на метрики по причинам возникновения багов и придумывали action items на будущее.
PR
Чтобы процесс работал, нужно рассказывать о нём новым и старым сотрудникам и работать над его репутацией. Находите команды, которые отлично работают по процессу, приглашайте их на встречи и рассказывайте про их историю успеха. Можно использовать такие инструменты:
- обучение: мастер-классы, статьи, онбординг,
- канал поддержки,
- пиар на внутренних комьюнити, общих встречах,
- дайджесты с отличниками и нарушителями процесса,
- бейджики.
Чтобы все новые сотрудники были в курсе процесса, я сделала курс в нашей базе знаний. Его добавили в онбординги сотрудников с простым тестом в конце, чтобы ребята могли проверить свои знания.
Поддержка команд по процессу
Иногда документация отвечает не на все вопросы. На этот случай у ваших коллег должна быть возможность оперативно получить ответ на свой вопрос.
У нас для этого был отдельный канал поддержки в мессенджере, чтобы информировать об обновлениях и изменениях процесса, отвечать на вопросы и собирать предложения по улучшениям и доработкам.
Дежурные
К сожалению, при отсутствии дежурных в командах правило «коллективной безответственности» часто прекрасно работает — участники команды надеются друг на друга и нарушают все сроки. Поэтому назначение дежурных снижает вероятность пропустить или не своевременно отреагировать на новый тикет.
У нас лучшие результаты всегда были в командах, в которых есть дежурные — такие команды работали с меньшим количеством просрочек.
Метрики
Чтобы понимать, как обстоят дела с процессом, без метрик обойтись сложно.
Поэтому ресурс аналитика может сильно пригодиться. Важны не только внешние метрики для команд, но и технические, которые нужны уже самим владельцам процесса. Это может быть доля тикетов без владельца, доля ошибок при проставлении приоритета или доля дубликатов.
Когда мы настраивали процесс, все дашборды были на мне — я неплохо разбираюсь в SQL и Tableau. Метрики для команд я добавила в дашборды кластеров, где были вкладки с метриками в динамике и с операционной вкладкой — «что надо было сделать ещё вчера». А для себя сделала отдельный дашборд с техническими метриками, который помогал видеть нарушения и узкие места процесса.
Как же развивать процесс?
Собрала несколько советов, которые могут помочь при настройке процесса, который регулирует получение и обработку обращений от пользователей:
- Процесс — это динамика, а значит со временем он будет меняться. Поэтому важно держать руку на пульсе и следить за внешними факторами: ростом аудитории, внешними обстоятельствами, появлением новых типов клиентов.
- Если вы занимаетесь настройкой процесса, не забывайте собирать фидбэк с его пользователей: саппорта, который создает тикеты, и техдепа, который их обрабатывает.
- Будьте открыты: общайтесь с вашими пользователями-коллегами, проводите опросы и кастдевы, смотрите на внутренние метрики. Это поможет оперативно находить несовершенные и устаревшие места процесса и улучшить их.
- При внедрении крупных изменений пилотируйте их на лояльных командах, а затем уже принимайте решение о раскатке на всех. Будьте готовы к тому, что не все ваши идеи доработок взлетят.
И еще — продумывайте возможные риски и пути их митигации. Например, у меня была карта в Miro, в которой я собирала весь фидбэк с разделением проблем и предложений с разной категоризацией: проблемы со стороны саппорта, теха, ASD. Там же можно было посмотреть варианты решений и уже предпринятые шаги с результатом. А еще мне сильно помогла схема всего процесса с полной детализацией от момента создания пользователем обращения до момента выкатки фикса в прод. Времени на нее ушло много, но зато было наглядно видно места доработок.
И главное — не бойтесь сложных процессов. Делитесь опытом с коллегами, любите своих пользователей и все обязательно получится.
В конце хочу сказать спасибо коллегам, которые помогали мне в настройке процесса — особенно поддержке и shsv.
Всем добра и меньше багов!
